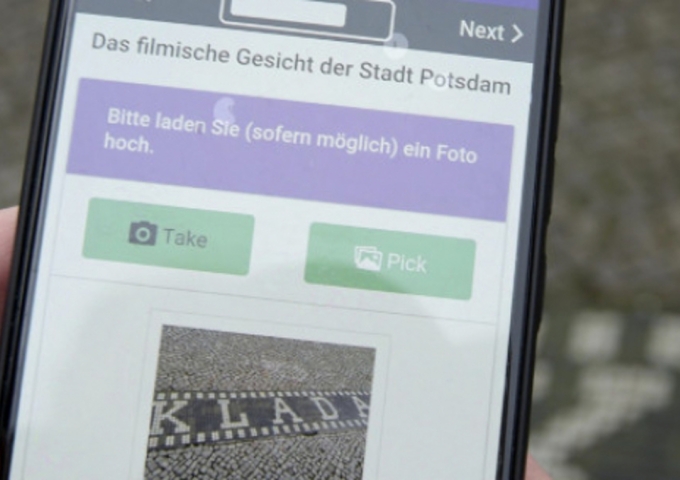
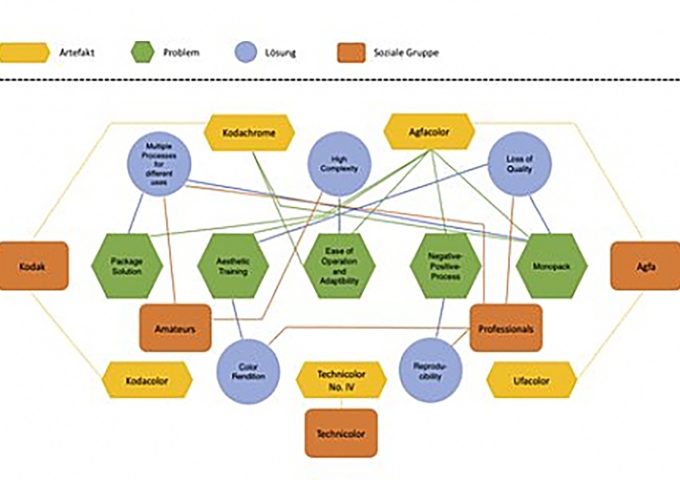
Open by default? The open data discourse suggests that it is always better to «open up» research data; hidden datasets do not help anyone besides the producing researchers themselves. Data produced with the support of public research funds must not be rotting away in a (depreciating) hard drive, a PDF table, or – beware – on an analogue piece of paper. Rather, research data should adhere to the FAIR data principles – hence, being searchable, accessible, interoperable and re-usable. However, as sociologist Bruno Latour highlights in his book Pandora’s Hope, opening up (amplification) always comes with a trade-off (reduction). In the process of data mobilization and standardization, we may gain compatibility and relative universality, but lose qualities such as locality, particularity, materiality, context and diversity. As much as FAIR data is a nobel objective and promising way to strive for open science in many academic fields (e.g. biology, computer science, physics), these principles may seem hard to work with for people handling qualitative or mixed (quant/qual) data, small data, highly heterogeneous, unstructured data, or analogue data.