
Scalable Viewing
Johannes Pause und Niels-Oliver Walkowski zu digitalen Methoden und den Digital Humanities (Teil 2)
Im ersten Teil dieses Beitrags wurde thematisiert, dass in der Diskussion um digitale Methoden die Unterschiedlichkeit der Bezüge zwischen Forschungsansätzen und digitaler Technologie vernachlässigt wurde. Unter anderem wurde dabei die Vorstellung kritisiert, dass statistisches Arbeiten den Kern dieser unterschiedlichen Methoden darstelle. Dies gilt, wie wir im zweiten Teil unserer Argumentation nun zeigen wollen, umso mehr, als dass sich das Arbeiten mit statistischen Modellen selbst im Zuge der Evolution digitaler Technologien nachhaltig verändert. Vor dem Hintergrund dieser Beobachtung wird jede Essentialisierung des Computers unmöglich, zeigt sich digitale Technologie doch als etwas, das selbst einem ständigen Wandel unterworfen ist. Dies kann an der Hervorhebung und Deutung einiger Merkmale der explorativen Datenanalyse und dem Einfluss, den technische Innovationen rund um das sogenannte Jupyter Notebook auf das Arbeiten mit statistischen Modellen ausüben, veranschaulicht werden.
Explorative Datenanalyse und das Jupyter Notebook
Ein vereinfachtes Modell datengetriebener Forschung, das in der Kritik am Feld immer wieder auftaucht, sieht als ersten Schritt zunächst die Verdatung des Forschungsgegenstands vor. Ihr folgt eine Analyse, die mit der Auswahl eines statistischen Modellbildungsverfahrens beginnt. Dieses Verfahren wird nun unter Bestimmung verfügbarer Parameter für eine Modellbildung verwendet, deren Ergebnis — das statistische Modell — einen statistischen Sachverhalt abbildet, welcher dem jeweiligen Interesse am Forschungsgegenstand entgegenkommt. Die Interaktion mit dem Forschungsgegenstand ist dabei programmatisch; Narrativität ist ein Mittel der Auswertung und des Berichtens.
Mit dieser Merkmalsbeschreibung sind, wie angedeutet, eine Reihe oftmals gegen die digitalen Methoden ins Feld geführter Einwände verknüpft, wie sie beispielhaft etwa in einem Beitrag von Allington, Brouillette und Golumbia formuliert wurden. Dabei wird auf die problematischen Folgen der Vereinfachungen hingewiesen, die lineare Konzeptualisierungen von Forschungsprozessen mit sich brächten, sowie die Unterkomplexität statistischer Modelle hervorgehoben, die zu unbrauchbaren oder uninteressanten Ergebnissen führten, weil sie qualitative Aspekte des Forschungsgegenstandes unterschlagen oder unzugänglich machten. Daran anschließend wird oft auf erkenntnis- und sinnstiftende Aspekte einer sinnlichen Erfahrung des Forschungsgegenstands verwiesen, die in einer rein numerisch und programmatischen Interaktion verloren ginge. Wie sich anhand des Jupyter Notebooks zeigen lässt, greift eine solche Kritik jedoch zu kurz.
Zellen: Interaktions- und Repräsentationsformen
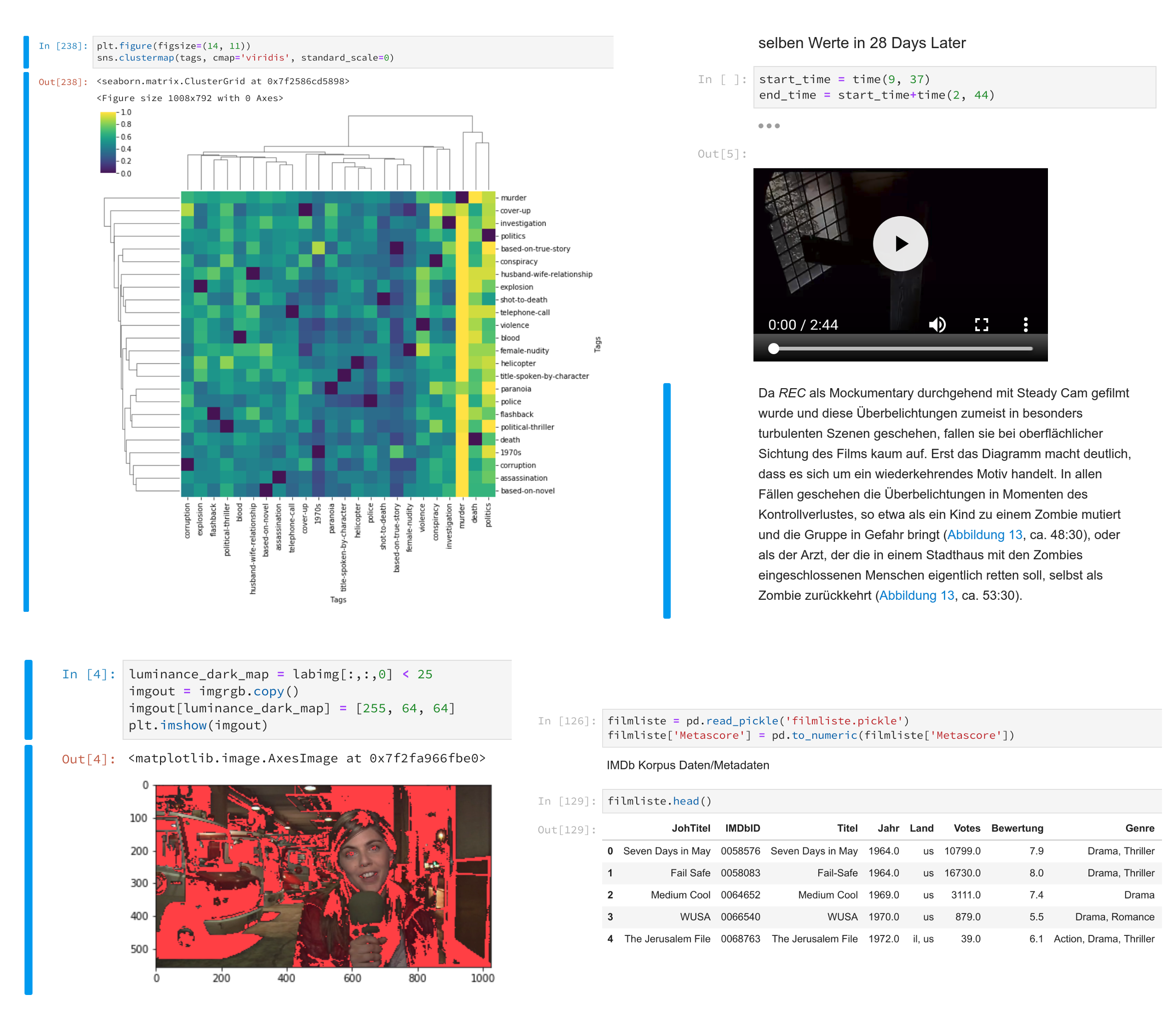
Abbildung 1: Beispiele unterschiedlicher Zellentypen im Kontext einer computergestützten Filmanalyse, die sich im Jupyter Notebook zu einem linear organisierten, multimedialen und multimodalen Narrativ zusammenfügen.
Das Jupyter Notebook, das zu den beliebtesten Arbeitsumgebungen im Data Science-Bereich zählt, ist zunächst nicht mehr als ein digitales Notizbuch. Es ermöglicht, während der Auseinandersetzung mit dem Forschungsgegenstand der Reihe nach Inhalte festzuhalten. Als interessant erweist sich jedoch ein Blick darauf, was für Inhalte dies sind und in welchem organisatorischen Zusammenhang sie stehen. Die Grundelemente des Notebooks sind die sogenannten Zellen, die, aneinandergereiht, den Inhalt des Notebooks erstellen. Dabei lässt sich zwischen verschiedenen Zelltypen unterscheiden, die in der Lage sind, jeweils andere Dinge zur Darstellung zu bringen und inhaltsspezifische Funktionalitäten bereitzustellen. So können etwa in textueller und formatierter Form eine Argumentation oder ein Gedankengang ausformuliert werden, verstreut kleine Programmschnipsel in verschiedenen Programmiersprachen ausgeführt, unterbrochen und an einer anderen Stelle des Notebooks wiederaufgenommen werden, es können Daten betrachtet oder visualisiert oder Bild-, Ton- und Videodateien eingepflegt werden. Eine explorative Datenanalyse stellt sich dabei gerade nicht als ein Prozess der ausschließlichen Verdatung mit anschließend algorithmischer Auswertung dar. Vielmehr ist die algorithmische, statistische und numerische Analyse Bestandteil einer multimodalen Konfiguration gleichberechtigter Repräsentations- und Analyseformen, die sich gegenseitig ergänzen.
Dynamik: Perspektive und Verdichtung
Abbildung 2: Interaktive Exploration der Veränderung von Merkmalen eines Datensatzes im Zusammenspiel mit unterschiedlichen Smoothing-Verfahren und variablen Parametern.
Der eingangs beschriebene, simplifizierte Ablauf eines auf digitale Methoden gestützten Forschungsprozesses reduzierte die Rolle der Statistik darauf, eine Reihe von Modellbildungsverfahren bereitzustellen, das effizienteste davon zur Anwendung zu bringen und schließlich ein Modell zu generieren, das der Logik eines Abbildes folgend einen Sachverhalt visualisierte. Gerade dieses Abbildverhältnis ist nicht selten berechtigte Ursache der Kritik an statistischen Verfahren. Im Jupyter Notebook werden statistische Modellgebungsverfahren jedoch nicht zwingend zu reinen Abbildungen, sondern — durch situative, selbstentworfene Dynamisierung und Interaktivität — vielmehr zu Möglichkeitsräumen (Abbildung 2). In diesen wird ein Forschungsgegenstand nicht lediglich abgebildet, er verhält sich in einer gewissen Weise, die aufs Neue zur Beobachtung zwingt. Natürlich ist ein Modellgebungsverfahren auch ein Modell — obgleich einer höheren Ordnung. Allerdings zielt das Jupyter Notebook — ebenso wie moderne Machine Learning-Bibliotheken wie zum Beispiel scikit-learn — immer schon auf eine gleichzeitige Arbeit innerhalb verschiedener solcher Modellgebungsverfahren ab (Abbildung 3). Diese Gleichzeitigkeit von Modellen, Dynamiken und Interaktionen (und der zuvor angesprochenen Multimodalität) führt nicht mehr zu einer Vereinfachung oder Reduktion von Komplexität, sondern initiiert ganz im Gegenteil einen Prozess der Vedichtung und pluralen Perspektivierung.
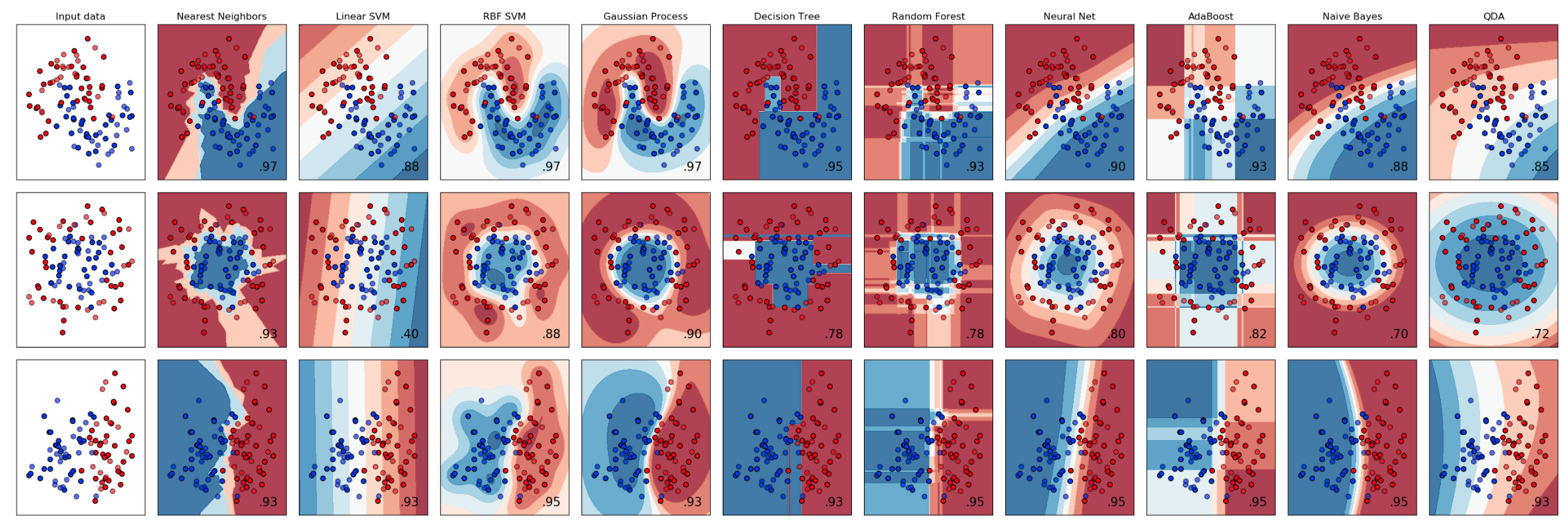
Abbildung 3: Exploration der Entscheidungsdispositionen unterschiedlicher Modellbildungsalgorithmen (x-Achse) in Interaktion mit drei Datensätzen (y-Achse). Quelle
Dashboards und Widgets: Interaktion und multimodale Interferenz
Die Dynamisierung der Interaktion wirft die Frage auf, welchen Status spezifische Merkmale innerhalb einer Repräsentationsform in einer anderen Repräsentationsform besitzen. Werden zum Beispiel Aspekte der Farbigkeit von Spielfilmen (siehe auch Barbara Flückiger in diesem Blog) in einem Diagramm wie auf Abbildung 4 untersucht, schließt sich unmittelbar die Frage an, auf welche Farbregionen des Frames sich die einzelnen Elemente des Diagramms beziehen: Wie sieht eine Koordinate im Diagramm in der visuellen Komposition des Bildes aus? Das Jupyter Notebook ermöglicht es, unterschiedliche Zellen, etwa Diagrammzellen oder Bildzellen, zu Widgets eines Dashboards zusammenzufügen und in einen funktionalen Zusammenhang zu stellen. Ein derartiger Zusammenhang ist in Abbildung 4 durch Algorithmen mit den Namen Histograming und Histogram Backprojection hergestellt worden. Wird nun ein visueller Reiz auf dem Frame selektiert, aktualisiert sich das Diagramm; wird hingegen ein Bereich auf dem Diagramm ausgewählt, werden Bilder und Aussparungen innerhalb der Bilder des Films neu berechnet. Ebenso kann das Abspielen eines Bewegtbildes zum Beispiel mit einer kontinuierlichen Aktualisierung einer Tabelle verbunden sein, die bestimmte für die Forschungsfrage relevante Aspekte des Materials aufzeigt. Insofern ist das Jupyter Notebook in der Lage, nicht nur ein multimodales, sondern auch ein vielfach inferierendes Setup zu erzeugen.
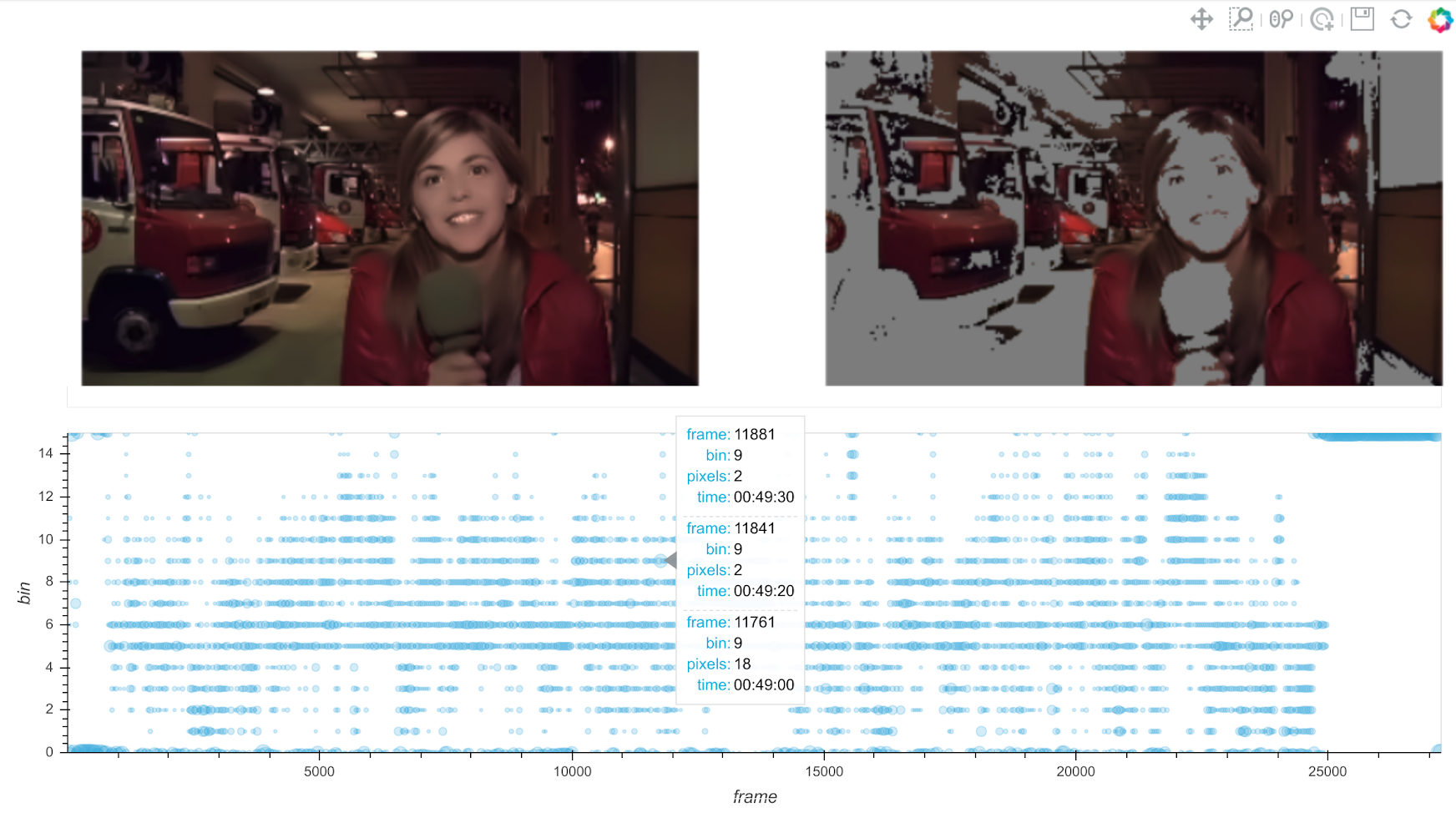
Abbildung 4: Repräsentation der numerischen, diagrammatischen und aisthetischen Merkmale eines Farbeffekts in einem interaktiven Filmanalyse-Dashboard, bestehend aus mehreren Widgets.
Scalable Viewing
Methoden datengetriebener Forschung können sich für medienwissenschaftliche Fragestellungen also gerade insofern als produktiv erweisen, als dass sie in der Lage sind, sich ihren Erscheinungsformen, Erzeugnissen und sozialen Einbettungen aus mehreren Perspektiven anzunähern. Viele der gegenüber digitalen Methoden geäußerten Vorbehalte, zum Beispiel jene des Reduktionismus, Empirismus oder Szientismus, erweisen sich als nicht länger haltbar, sobald diese als Werkzeuge im Rahmen einer vielgestaltigen Praxis konzipiert werden, in der der Einsatz der Mittel nicht unmittelbar mit wissenschaftspolitischen Grundsatzentscheidungen zusammenfällt. Gerade auf der Ebene der Praxis, also im Kontext konkreter Forschungsprojekte, lässt sich dabei beobachten, dass computergestützte Arbeitsumgebungen den genannten Gefahren zusehends entgegenzuwirken suchen, zumal die Funktion des Computers in der Forschung in der Regel die eines Multiplikators und Diversifizierers ist.
Die Multiplikation von Ansätzen und Perspektiven lässt sich dabei wiederum selbst konzeptionell fassen. In Erweiterung des von Thomas Weitin am deutschen Novellenschatz erprobten Konzepts des Scalable Readings wollen wir für eine Auseinandersetzung mit Medienerzeugnissen, die in der Regel eine ästhetische Dimension aufweisen, den Begriff Scalable Viewing vorschlagen. Er nimmt auf das Konzept des Distant Reading Bezug, mit dem Franco Moretti einst eine rein quantitative Erfassung großer literarischer Korpora beschrieb1 und das oftmals mit computerisierten Forschungsmethoden in den Geisteswissenschaften insgesamt gleichgesetzt wird. ‹Distanziertes Lesen› soll eine abstrakte Repräsentation literarischer Werke ermöglichen, die auf der Grundlage bestimmter Vorentscheidungen in Daten und Diagramme übersetzt und so großmaßstäblich vergleichbar gemacht werden. Die Vogelperspektive etwa auf die Entwicklung einer ganzen literarischen Gattung über mehrere Jahrzehnte hinweg eröffnet dabei unweigerlich Einsichten, die aus einer am literarischen Text selbst ‹klebenden› Lektüre unmöglich zu gewinnen wären.
Freilich nimmt eine in dieser Form distanzierte Perspektive Verluste in Kauf, indem sie dasjenige, was an den literarischen Werken kommensurabel ist, isoliert. Unklar bleibt allerdings, weshalb die Entscheidung für das Distant Reading einen Dialog mit anderen Perspektiven ausschließen soll. Scalable Reading ist daher weniger eine konkrete Methode als ein im konkreten Forschungskontext näher auszugestaltendes Programm, das die Verbindung zu den traditionelleren Methoden der Literaturwissenschaft wiederherstellt. Weitin schreibt:
Das Konzept des Scalable Reading schließt prinzipiell alle Akte des Lesens und Analysierens von Texten ein, wobei davon ausgegangen wird, dass wir es in der Regel schon beim verstehenden Lesen mit Text-›Surrogaten‹ zu tun haben. Wer die Oxford-Klassiker-Ausgabe der Odyssee liest [...], ist im Grunde bereits ein ‹distant reader› der Gesänge, die Homer zugeschrieben worden sind. Und gerade der distant reader im herkömmlichen Verständnis, der mit digitalen Analysen Daten und Visualisierungen erzeugt, muss diese verstehen und interpretieren. ‹Scalable Reading› bedeutet indes nicht nur, dass sich close und distant reading methodisch durchdringen, es steht für ein integriertes Verständnis aller Akte des Lesens und Untersuchens auf einer weiten ‹scale› medialer Formen und analytischer Aufbereitungen. Das reicht vom analogen Textdruck über digitalisierte Textkorpora bis hin zu digitalen Surrogaten, die auf der Grundlage von Worthäufigkeitslisten Delta Scores ermitteln [...] oder den Fließtext in ein bag of words umwandeln, um ihn modellieren zu können.2
Das von uns vorgeschlagene Konzept des Scalable Viewings wiederum überträgt diese vermittelnde Perspektive nicht allein auf die epistemischen Objekte der Medienwissenschaft, es definiert die Leistung computergestützter Analyseverfahren gerade dahingehend, dass unterschiedliche Formen des Zugriffs auf das Material durch diese selbst immer von Neuem angeregt werden. Die Skalierung dient nicht der Kompensation der einen (positivistischen, distanzierten, auf Big Data ausgerichteten) digitalen Methodik, vielmehr ist die Pluralisierung von Perspektiven auf das Untersuchungsmaterial selbst das Resultat eines durch computerisierte Verfahren erweiterten wissenschaftlichen Möglichkeitsraums.
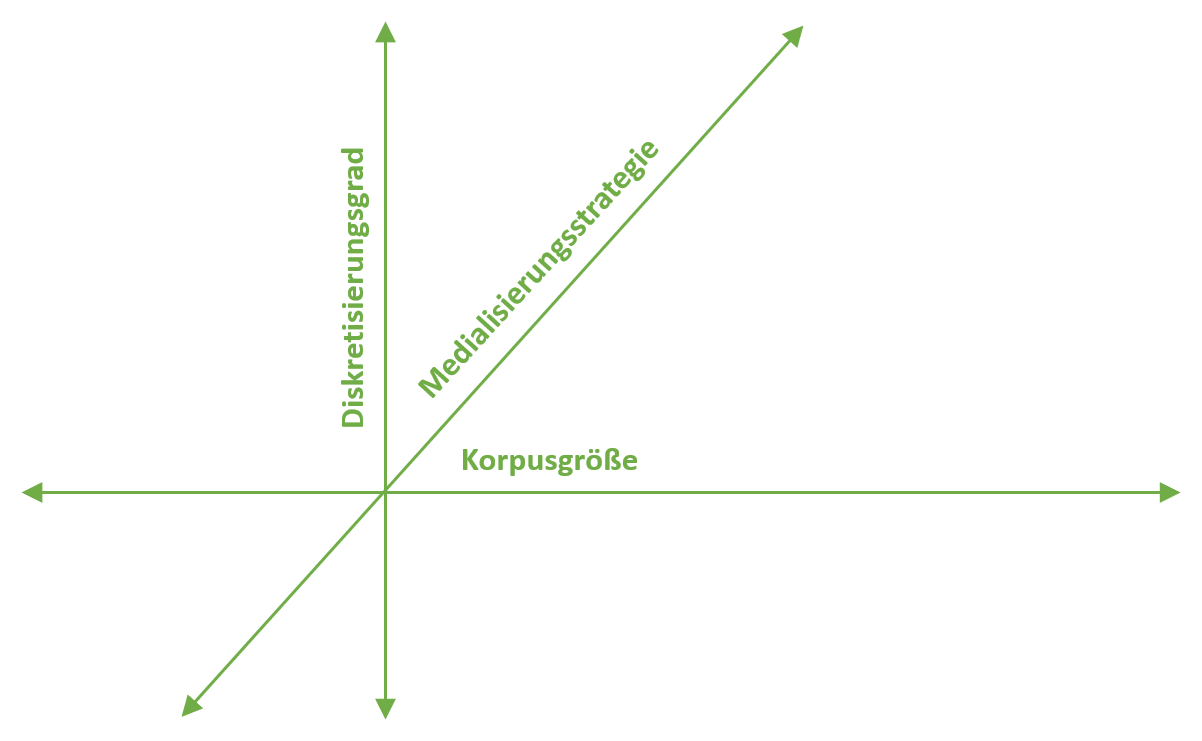
Abbildung 5: Die drei Achsen des Scalable Viewing.
Das von Weitin implizit vorausgesetzte 2-Achsen-Modell, in dem auf der einen Achse die Entfernung zum einzelnen Werk und mithin die Größe des untersuchten Korpus, auf der anderen der Grad der Medialisierung oder Verdatung der Werke vermerkt ist, wird in unserem Konzept aus diesem Grund zu einem 3-Achsen-Modell umgestaltet (vgl. Abbildung 5). Die erste Achse misst dabei den Grad von Formalisierung und Abstraktion und vermittelt auf diese Weise zwischen Close und Distant Reading, wobei Distanz hier in erster Linie meint, dass bestimmte Aspekte eines Werkes isoliert und in Form von Daten oder Diagrammen dargestellt werden. Von der Frage der Abstraktheit unabhängig ist die Korpus-Achse, auf der von der Auseinandersetzung mit einem einzelnen Werk auf kleinere oder mittelgroße Korpora und schließlich auf Big Data umgeschaltet werden kann. Die dritte Achse ist den methoden- oder theoriegeleiteten Zugriffsweisen der Forscherin selbst gewidmet, die manchmal eine genaue, korrelierende Abbildung eines bestimmten Sachverhalts herstellt, dann wieder mit flexibel dynamisierbaren, vielgestaltigen Repräsentationen des Materials frei arbeitet, um neue Perspektiven zu entwickeln, die im Anschluss wiederum formalisiert und in ihrer Auswahl möglicher Repräsentationen integriert werden können. Die Achsen markieren somit keine Gegenüberstellung verschiedener unvermittelbarer Forschungsparadigmen, sondern systematisieren die unterschiedlichen Perspektiven, die im Verlauf eines einzigen Forschungsprozesses auf ein bestimmtes Material eingenommen werden können.
Verhindert werden soll durch diese Differenzierung vor allem eine zu rasche Gleichsetzung computergestützter Methoden mit Big Data: Wie wir andernorts am Beispiel eines filmanalytischen Zugriffs zu zeigen versucht haben, schließen sich etwa ein vergleichendes Close Reading einiger weniger Werke und die Generierung hochgradig abstrakter Daten und digitaler Surrogate keineswegs aus.3 Der Einsatz computergestützter Methoden in einem solchen Kontext eröffnet freilich immer auch die Perspektive einer erweiterten Anwendung auf große Korpora, er kann aber auch ohne diese Perspektive aussagekräftige Daten erzeugen. Jede Achse ist, je nach Forschungsinteresse, im Prinzip gleichermaßen frei skalierbar.
Ein solches Modell ist nicht mehr identisch mit einer Methode, es skizziert vielmehr ein Feld, in dem sich Methodologisierungsprozesse überhaupt erst einleiten lassen. Friederike Schruhl weist in diesem Sinne darauf hin, dass Verfahren des Close, Micro, Deep, Distant, Macro oder Wide Readings selbst noch keine Methoden festlegen; vielmehr handelt es sich um lose Bündelungen von Zugriffsformen, die unterschiedlichsten Zwecken dienen können: «Das Scalable Reading würde in einer solchen Perspektive zu einem programmatischen Hinweis oder tatsächlich zu einem ‹Konzept› avancieren, das [...] auf das weite Spektrum literaturwissenschaftlicher Zugriffsweisen und die unterschiedlichen Kombinationen des Objektumgangs verweist.»4
Ein Verständnis der Digital Humanities als Set konkreter Methoden, die sich von anderen Methoden klar abgrenzen lassen, erweist sich mithin als Lose-Lose-Situation, da sowohl das Potenzial digitaler Technologie ungenutzt bleibt als auch die wissenschaftlichen Verfahren selbst sich grundlose Einschränkungen auferlegen. Ein anschlussfähiges Konzept digitaler Geisteswissenschaft hingegen sollte den eher experimentellen Weg einer epistemischen Bastelei einschlagen, in welcher Zugriff wie Untersuchungsobjekt erst im Prozess emergieren.5 Einen konkreten Anwendungsfall liefert hier etwa die digitale Geschichtswissenschaft, wenn sie den Reiz der neuen database histories in der Möglichkeit entdeckt, «sich von vorgefertigten und argumentativer Kohärenz geschuldeten Meistererzählungen zu emanzipieren».6 Dagegen bleibt jede neue Meistererzählung, die digitale Methoden als Vehikel benutzt, die Geisteswissenschaften auf eine bestimmte Art des Fortschritts zu verpflichten, nicht nur hinter den Möglichkeiten digitaler Technologien zurück – sie scheitert auch zuverlässig an ihrem Anspruch, innerhalb dieser Entwicklung Orientierung zu stiften.
Mehrteilige Reihe
- Taxonomien computergestützter Forschung. Johannes Pause und Niels-Oliver Walkowski zu digitalen Methoden und den Digital Humanities, Teil 1
- Scalable viewing. Johannes Pause und Niels-Oliver Walkowski zu digitalen Methoden und den Digital Humanities, Teil 2
- 1Vgl. Franco Moretti: Distant Reading, Konstanz 2016.
- 2Thomas Weitin: Scalable Reading. Paul Heyses Deutscher Novellenschatz zwischen Einzeltext und Makroanalyse, Kreuzlingen 2015, Kap. 2.
- 3Vgl. Johannes Pause, Niels-Oliver Walkowski: Everything is Illuminated. Zur Numerischen Analyse von Farbigkeit in Filmen, in: Zeitschrift für digitale Geisteswissenschaften, Wolfenbüttel 2018. DOI: 10.17175/2018_003.
- 4Friederike Schruhl: Objektumgangsnormen in der Literaturwissenschaft, in: Zeitschrift für digitale Geisteswissenschaften, Wolfenbüttel 2018. DOI: 10.17175/sb003_012.
- 5Vgl. Hans-Jörg Rheinberger: Experiment. Präzision und Bastelei, in: Christoph Meinel (Hg.): Instrument – Experiment. Historische Studien, Berlin 2000, 52–60.
- 6Andreas Fickers: Entre vérité et dire du vrai. Ein geschichtstheoretischer Grenzgang, in: Andreas Fickers, Rüdiger Haude, Stefan Krebs, Werner Tschacher (Hg.): Jeux sans Frontières? Grenzgänge der Geschichtswissenschaft, Bielefeld 2017, 29–40, hier 31.
Bevorzugte Zitationsweise
Die Open-Access-Veröffentlichung erfolgt unter der Creative Commons-Lizenz CC BY-SA 4.0 DE.