
Digitale Medien und Methoden
Zur Offenheit digitaler Methoden, Infrastrukturen und Daten in der medienwissenschaftlichen Analyse sozialer Netzwerke
In unserem Beitrag Die Medienwissenschaft im Lichte ihrer methodischen Nachvollziehbarkeit haben wir (Laura Niebling, Felix Raczkowski, Maike Sarah Reinerth und Sven Stollfuß) dazu aufgerufen, über «gegenstandsbezogene Methoden und Ansätze» zu sprechen. Zur Vorbereitung auf das von uns in diesem Zusammenhang geplante Methoden-Handbuch Digitale Medien und als Beitrag zu einer offenen Methodendiskussion im Fach kuratieren wir in den kommenden Monaten eine Sonderreihe zu «Digitale Medien und Methoden» im Open-Media-Studies-Blog mit ‹Werkstattberichten› zu den in der medienwissenschaftlichen Forschung eingesetzten Methoden.
Der neunte Beitrag der Sonderreihe stammt von Simon David Hirsbrunner und thematisiert Fragen des Zugangs zu technischen Infrastrukturen digitaler Medienforschung.
Unter dem Begriff ‹Open Science› werden derzeit vielfältige Aspekte wissenschaftlicher Praktiken neu verhandelt.1 Wie in diesem Blog bereits von Jeroen Sondervan thematisiert wurde, stellen sich auch in der Medienwissenschaft verschiedene Fragen zur Offenheit der Forschung, wobei dies weit über die Thematik des Open Access zu wissenschaftlichen Publikationen hinausgeht. Forschungsrelevante Zugangsbarrieren können sich auf Methodenwissen beziehen, auf Werkzeuge, auf Quellen, auf Fördergelder oder auf den Zugang zu Schlüsselpositionen und -institutionen. Auf neue Weise stellen sich Fragen der Offenheit in einer digitalen Medienforschung, welche methodisch zwar qualitativ angelegt ist, aber zunehmend mit informatisch geprägten Verfahren experimentiert. Im Folgenden möchte ich Aspekte von Offenheit, Zugang und Teilhabe am Beispiel der kritischen Plattform- und Social Media (SM) Forschung thematisieren. Der Fokus auf diesen Teilbereich der Medien- und Internetforschung bietet sich an, da er in besonderem Maße durch digitale Technologien und Infrastrukturen vermittelt wird.
Im Kontext dieses Beitrags verstehe ich digitale Methoden nach Richard Rogers als «techniques for the study of societal change and cultural conditions with online data»2. Anders als im Sprachgebrauch der Digital Humanities handelt es sich bei digitalen Methoden dieser Lesart meist um wissenschaftliche Praktiken mit bestehenden Instrumenten, welche unter relativ überschaubarem Aufwand für die Sozial- und Medienforschung umfunktioniert werden. So wird hier unter anderem mit den APIs (Application Programming Interfaces) sozialer Medienplattformen experimentiert, um Wissen zur Dynamik ihrer Algorithmen, Benutzer_innen-Interaktionen und anderer Phänomene zu erarbeiten. Anders als in der informatischen Netzwerkforschung werden die Tools nicht so sehr als zielorientierte Instrumente verstanden, sondern als Elemente einer reflexiven Methodologie. In dieser reflexiven Ausrichtung digitaler Methoden muss auch die Frage gestellt werden, wie offen und zugänglich diese Art technisch-vermittelter Forschung ist. Welcher Zugang zu Technologien, Infrastrukturen und Daten ist notwendig, damit eine solche Forschung stattfinden kann? Welche Fertigkeiten müssen Forschende mitbringen, erarbeiten oder in Kollaboration einbringen, um mit digitalen Methoden arbeiten zu können?
Offene Technologien
Verschiedene wissenschaftliche Einrichtungen stellen digitale Toolboxen für die Medien- und Internetforschung zur Verfügung. Zwei Beispiele für besonders umfassende Linksammlungen sind die Tool-Webseiten der Digital Methods Initiative (DMI) an der Universität Amsterdam und dem médialab der Science Po Paris. Die dort verlinkten Instrumente ermöglichen Prozesse wie das Extrahieren (web scraping) von URLs aus Webseiten, aber auch komplexe Verfahren wie das Sammeln und Verfügbarmachen von Daten aus SM-Plattformen. Beispiele für derartige Instrumente sind TCAT (Twitter Capturing and Analysis Toolset), netvizz (Facebook) und die YTDT (YouTube Data Tools).
Werkzeuge
In meiner eigenen Forschung verwende ich beispielsweise die YTDT, um Kommentare und andere Nutzerdaten zu Debatten wissenschaftlicher Themen auf YouTube zu extrahieren, um so Neukonfigurationen des Vertrauens in wissenschaftliche Expertise zu analysieren. Dazu rufe ich die Webseite der YTDT auf und wähle dort das ‹Video Info and Comments Module› aus. Anschließend gebe ich die Identifikationsnummern der für meine Forschung relevanten Videos in ein Textfeld ein, löse ein reCAPTA und drücke ‹Senden›. Der YTDT-Server versendet dann meine Datenbank-Anfrage an die YouTube-API und ich erhalte die Ergebnisse als Dateien zum Download, sowie zusätzlich als HTML-Tabellen direkt im Browser. Nach dem Herunterladen der Dateien (in Formaten wie .tab, .csv und .gdf) können die Datensets in unterschiedlicher Analyse-Software weiterverarbeitet werden, also beispielsweise in Gephi, MAXQDA, Tableau, MS Excel, oder für Programmierversierte in R Studio und Python Jupyter Notebooks.

Abbildung 1: Video Info and Comments Module der YouTube Data Tools während der Extraktion von Daten zu video id xE0KtLy5j8w (Quelle: https://tools.digitalmethods.net/netvizz/youtube/)
Benutzeroberflächen
Eine herausragende Leistung der Tools ist, dass sie Medienforscher_innen den Zugang zu Technologie, Daten und Wissen verschaffen, die sonst einer kleinen Gruppe von Informatiker_innen und Datenwissenschaftler_innen in Forschung und Industrie vorbehalten sind. Sie führen damit zu einem ‹empowerment› kritischer Medienforschung gegenüber den mächtigen Konstellationen der Plattform-Ökonomie und Data Science. Unter anderem stellen Instrumente wie TCAT und YTDT graphische Benutzeroberflächen für API-Abfragen bereit, ohne dass diese wie üblich über eine Kommandozeile formuliert und eingegeben werden müssen (siehe Abbildung 1).
Infrastrukturen
Es ist wichtig zu betonen, dass Instrumente wie TCAT oder YTDT keinen direkten, unvermittelten Zugang zu Plattformen und deren Daten herstellen. Zwischen den visuellen Benutzeroberflächen und den sozialen Medienplattformen sind jeweils recht komplexe Infrastrukturen der Forschungsinstitutionen zwischengeschaltet, welche die API-Abfragen vorformulieren. Bei komplexeren Tools wie TCAT werden Daten in definierten Zeitabständen über die APIs abgefragt, sie werden auf Universitäts-Servern gespeichert, neu strukturiert, formatiert und für später zur Abfrage durch die Forschenden freigegeben.
Die Zugänglichkeit der Tools variiert dabei je nach Aufbau der angesprochenen API und den entsprechenden Nutzungsbedingungen der relevanten SM-Plattform. Entsprechend enthält etwa die DMI-Webseite den Hinweis, dass wegen der Twitter-Nutzungsbedingungen leider nur Masterstudierenden der Universität Amsterdam ein Zugang zu TCAT gegeben werden darf. Während meiner Promotionsphase konnte ich glücklicherweise die TCAT-Instanz des Siegener Sonderforschungsbereichs Medien der Kooperation nutzen, wobei deren Zugang eben auch auf Angehörige der Universität beschränkt ist. Auch müssen Server gewartet und die jeweiligen Nutzer_innen beraten werden, was typischerweise über die Kapazitäten und Fertigkeiten der IT-Dienste von Universitäten hinausgeht. Vermehrt werden solche Arbeiten deshalb von wissenschaftlichen Programmierer_innen (scientific programmer) übernommen, die erst einmal gefunden, bezahlt und in einem dynamischen Stellenmarkt auch gehalten werden müssen.
Offene Daten
Die beschriebenen Werkzeuge, Benutzeroberflächen und Infrastrukturen ermöglichen den Zugang zu Daten, welche für die digitale Medienforschung nutzbar gemacht werden können. In meiner Forschung sind dies beispielsweise Interaktionsdaten zum Video The World After Sea-Level Rise (siehe Abbildung 2). Die Daten werden in eine Analyse-Software (siehe oben) geladen und im konkreten Fall anhand qualitativer Coding-Verfahren3 kategorisiert. Anhand der Daten und Codes konnte ich diskursive Praktiken des Umgangs mit wissenschaftlichen Klimaszenarien identifizieren und charakterisieren – beispielsweise ‹Akteure mobilisieren›, ‹Klimafolgen lokalisieren›, ‹Repräsentation einfordern›, ‹an populäre Narrative anknüpfen›, ‹Informationen relativieren›, ‹Wissenschaft diskreditieren› und ‹Verschwörung konstatieren›.
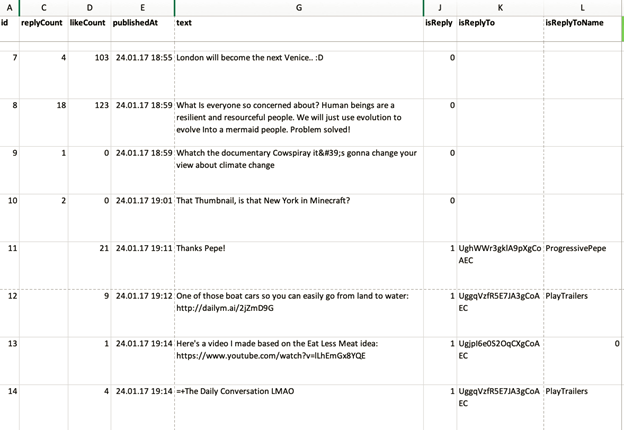
Abbildung 2: Auszug aus Daten zu video id xE0KtLy5j8w. Nicht anonymisiert, da meines Erachtens keine Risiken für genannte Nutzer_innen bestehen. (Quelle: eigene Darstellung)
In der informatischen Social-Media-Analyse hat sich teilweise die problematische Vorstellung etabliert, dass es sich bei solchen Social-Media-Daten (SMD) um ein öffentliches Gut im Sinne von ‹open data› handelt.4 Dabei muss die Offenheit von SMD in vielerlei Hinsicht differenziert oder in Frage gestellt werden.5 Für die Qualifizierung der Offenheit von SMD spielen verschiedene Aspekte eine Rolle, die in diesem Blog-Format nur kurz angerissen werden können.
Parallele Öffnungen und Schließungen
Die Tendenz bei SMD geht bei weitem nicht unidirektional, in Richtung einer Öffnung von Daten, sondern ebenso in einer Gegenbewegung in Richtung einer Verschließung von APIs zu Forschungszwecken. So hat insbesondere die Facebook-Gruppe (Facebook, Instagram, WhatApp, etc.) im Nachgang des Cambridge Analytica Skandals den Zugang zu APIs und Daten wesentlich erschwert.
Als Konsequenz davon wurden wissenschaftlich ausgelegte Tools wie netvizz unbrauchbar gemacht, was der kritischen Facebook-Forschung einen schweren Schlag versetzt hat.6 Nun mag man sich als Forscher rechtlich relativ unbedenklich über die Grenzen der Plattform-APIs hinwegsetzen. Dennoch stehen durch die restriktivere API-Politik eben einige Daten nicht mehr zur Verfügung, bzw. können sie nur durch sehr viel aufwendigere Verfahren extrahiert und zugänglich gemacht werden.
Juristische und ethische Aspekte
Zweitens ergeben sich durch die zunehmende Verteiltheit digitaler Forschungsinfrastrukturen juristische und ethische Herausforderungen. So werden Daten oft von Forschenden einer Institution erhoben, aber von der Infrastruktur einer anderen Institution verarbeitet (e.g. DMI), dann zwischen Kolleg_innen und mit Studierenden geteilt und womöglich auf kommerziellen Cloud-Diensten (GoogleDrive, Dropbox, etc.) zwischengespeichert. Nach Ansicht mehrerer informell befragten Rechtsexpert_innen steht diese Praxis juristisch auf höchst wackeligen Beinen. Nun mag eingeworfen werden, dass beispielsweise Tweets (anders als WhatsApp-Nachrichten, Kommentare aus geschlossenen Facebook-Gruppen, etc.) öffentlich gepostet wurden und somit nicht dem Datenschutz unterstehen. Juristisch ist dies jedoch zumindest im Geltungsraum der Datenschutz-Grundverordnung (DSGVO), also in der Europäischen Union, nicht so einfach. Zwar hat der/die Nutzer_in mit ihrem Posting akzeptiert, dass ihre Meinungsäußerung auf Twitter und übers Netz frei zugänglich ist. Allerdings dürfen der Tweet und dessen Metadaten nicht einfach so aus ihrem Nutzungskontext (Twitter Plattform) gelöst und anderweitig verarbeitet und/oder abgebildet werden. Für die DSGVO ist der Tweet ein personenbezogenes Datum, welches verschiedenen Auflagen wie beispielsweise dem Auskunftsrecht betroffener Personen (Art. 14 DSGVO) unterliegt. Nun ist es mit Blick auf den Umfang von SM-Datensets unmöglich, jedem/jeder erwähnten/erwähnter Nutzer_in eine Information und Einverständniserklärung zu Forschungszwecken zukommen und diese unterschreiben zu lassen. Allerdings mag es in den meisten Fällen auch keinen realistischen Grund für die Durchsetzung der Verordnung gegenüber einzelnen Forschenden geben. Dennoch müssen sich die Wissenschaftler_innen bewusst sein, dass sie in einem juristischen Graubereich operieren, in welchem situativ angepasstes und ethisch-sensibilisiertes Handeln geboten ist. Ansätze, welche derzeit unter dem Begriff der differential privacy7 diskutiert werden, mögen hierzu interessante konzeptionelle Anknüpfungspunkte bilden.
Besonderheiten qualitativer Medienforschung
Drittens muss uns als Medienwissenschaftler_innen bewusst sein, dass sich viele der dargestellten Problematiken nicht generell für die Wissenschaft, sondern spezifisch für qualitativ ausgerichtete Forschung ergeben. In der quantitativ ausgerichteten sozialen Netzwerkforschung haben sich recht effektive Verfahren herausgebildet, um datenschutzrechtliche Aspekte mitzudenken und dennoch sinnhafte Erkenntnisse zu erarbeiten und Ergebnisse darstellen zu können. Es wird zwar im Forschungsprozess mit personenbezogenen Daten gearbeitet, allerdings werden diese spätestens für die abschließende Publikation anonymisiert. Dies ist relativ einfach möglich, da die Ergebnisse als Trends, Korrelationen und Verbindungen präsentiert werden. Identitäten und Aktionen einzelner User_innen sind dagegen in einem solchen Forschungskontext größtenteils irrelevant und können ohne Gefahr eines Qualitäts- und Evidenzverlusts unsichtbar gemacht werden. In der qualitativen Forschung ist es dagegen schwierig, Bezüge zu individuellen Akteuren und deren situierten (Inter-)Aktionen komplett unsichtbar zu machen. Diese Thematik ist natürlich für die qualitative Sozialforschung nichts grundsätzlich Neues.8 Dennoch kollidieren etablierte Methoden der Anonymisierung und Pseudonymisierung in der qualitativen Forschung eben in besonderem Masse mit der Nachverfolgbarkeit von Interaktionen in digitalen Plattformen. So ist es im Vergleich zu qualitativen Interview-Transkripten und ethnographischen Feldnotizen bei SMD noch schwieriger, eine Anonymisierung oder Pseudonymisierung von Identitäten vorzunehmen, ohne dass der für die Argumentation zentrale Kontext verloren geht. Wie ich in meiner eigenen Forschung erfahre, ist die Verhandlung eines Youtube Kommentars ohne Möglichkeit der Nennung des YouTube Kommentars eine analytische und rhetorische Herausforderung.
Fazit
In diesem Beitrag wurden ausgewählte Aspekte zur Offenheit digitaler Methoden in der Medienforschung thematisiert. Ausgehend von meiner eigenen Forschung habe ich dabei auf Aspekte des Zugangs zu Technologien und das Teilen von Daten fokussiert. Dabei habe ich insbesondere darauf hingewiesen, dass Offenheit von und Teilhabe an digitalen Methoden finanziell, technisch und personell gut ausgestattete Forschungseinheiten und -institutionen voraussetzen. Offene Infrastrukturen und Technologien in der Forschung mit digitalen Methoden sind in der Aufrechterhaltung aufwändig und als Bestandteil menschlicher und nicht-menschlicher Care-Arbeit weder kosten- noch zeitlos.
Zudem ist deutlich geworden, warum die in den Naturwissenschaften beliebte Dichotomie zwischen ‹geschlossenen› und ‹offenen› Daten9 in der digitalen Medienforschung nicht zielführend ist. Im Zuge einer kritischen und situativen Bewertung von Offenheit könnte aber in Zukunft besser ausdifferenziert werden, welche Daten mit wem wann wo geteilt werden können, ohne dass juristische oder ethische Aspekte in Mitleidenschaft gezogen werden.
Durch die Verpflichtungen zu formalisierten Forschungsdatenmanagement-Plänen seitens Förderinstitutionen sind dies alles keine Herausforderungen, die sich langfristig durch pragmatische ‹bricolage› adressieren lassen. Auch werden sich vor dem Hintergrund der jetzt geflissentlich angelegten SMD-Sammlungen zu COVID19 insbesondere die Fragen zum Teilen von SMD noch einmal neu stellen. Eine stärkere Sensibilisierung und ein Meinungsaustausch unter Medienforscher_innen zu eben diesen Themen wäre hier sinnvoll und angebracht.
- 1vgl. Benedikt Fecher, Sascha Friesike: Open Science: One Term, Five Schools of Thought, in: Opening Science, o. O. 2014, 17–47, online unter https://link.springer.com/chapter/10.1007/978-3-319-00026-8_2, gesehen am 19.4.2018.
- 2Richard Rogers: Digital Methods for Web Research, in: Robert A Scott,, Stephen M Kosslyn (Hg.): Emerging Trends in the Social and Behavioral Sciences: An Interdisciplinary, Searchable, and Linkable Resource, o. O. 2015, hier 1, online unter http://proxy.library.cornell.edu/login?url=http://onlinelibrary.wiley.com/book/10.1002/9781118900772, gesehen am 18.9.2015.
- 3vgl. Kathy Charmaz: Constructing Grounded Theory: A Practical Guide through Qualitative Analysis, London; Thousand Oaks, Calif. 2006, 42 ff.
- 4vgl. dazu beispielhaft Chen, Siming, Lijing Lin, and Xiaoru Yuan. “Social Media Visual Analytics.” Computer Graphics Forum 36, no. 3 (2017). https://www.researchgate.net/publication/318203022_Social_Media_Visual_Analytics. Ullah, Ihsan, Caoilfhionn Lane, Brett Drury, Marc Mellotte, and Michael G Madden. “Open Social Data Crime Analytics.” Conference: International Workshop on Artificial Intelligence in Security, 2017.
- 5Es ist kein Zufall, dass diese undifferenzierte Begrifflichkeit insbesondere in der Nähe der Intelligence-Community und Predictive Analytics auftaucht, in der SMD unter ‹open intelligence› (OSINT) laufen. Vgl. beispielhaft Omand, Sir David, Jamie Bartlett, and Carl Miller. “Introducing Social Media Intelligence (SOCMINT).” Intelligence and National Security 27, no. 6 (December 1, 2012): 801–23. https://doi.org/10.1080/02684527.2012.716965.
- 6vgl. Marco Bastos, Shawn T. Walker: Facebook’s Data Lockdown Is a Disaster for Academic Researchers, 11.4.2018, online unter http://theconversation.com/facebooks-data-lockdown-is-a-disaster-for-academic-researchers-94533, gesehen am 10.7.2020; Tristan Hotham: Facebook Risks Starting a War on Knowledge, 17.8.2018, online unter http://theconversation.com/facebook-risks-starting-a-war-on-knowledge-101646, gesehen am 10.7.2020.
- 7vgl. Yin Yang, Zhenjie Zhang, Gerome Miklau, Marianne Winslett, Xiaokui Xiao: Differential Privacy in Data Publication and Analysis, Scottsdale, Arizona, USA, 2012, 601, online unter http://dl.acm.org/citation.cfm?doid=2213836.2213910, gesehen am 5.8.2020.
- 8vgl. Isabel Steinhardt, Caroline Fischer, Maximilian Heimstädt, Simon David Hirsbrunner, Dilek İkiz-Akıncı, Lisa Kressin, Susanne Kretzer, Andreas Möllenkamp, Maike Porzelt, Rima-Maria Rahal, Sonja Schimmler, René Wilke, Hannes Wünsche: Das Öffnen und Teilen von Daten qualitativer Forschung: Ergebnisse eines Workshops der Forschungsgruppe „Digitalisierung der Wissenschaft“ am Weizenbaum Institut in Berlin am 17. Januar 2020, in: Weizenbaum Series dort datiert 2020, online unter https://www.ssoar.info/ssoar/handle/document/67797, gesehen am 28.5.2020.
- 9Mark D. Wilkinson, Michel Dumontier, IJsbrand Jan Aalbersberg, Barend Mons u. a.: The FAIR Guiding Principles for Scientific Data Management and Stewardship, in: Scientific Data, Bd. 3, 15.3.2016, 160018.
Bevorzugte Zitationsweise
Die Open-Access-Veröffentlichung erfolgt unter der Creative Commons-Lizenz CC BY-SA 4.0 DE.