
Die Vermessung der medienwissenschaftlichen Welt?
Datengestützte Analysen mit media/rep/
Einleitung
Die Frage nach den Methoden und dem epistemologischen Zugriff der Medienwissenschaft wird seit einiger Zeit intensiv geführt.1 Dieser Beitrag widmet sich quantifizierenden Verfahren, will jedoch nicht Partei ergreifen für eine umfassende Verdatung oder Datifizierung des Faches.2 Im Sinne eines Methodenpluralismus und einer Vielfalt an Zugängen stellen wir vielmehr vor, wie sich bestehende Forschungsinfrastrukturen für datengestützte Analysen nutzen lassen. Hierzu legen wir im Folgenden unser Vorgehen bei der Arbeit mit bestehenden Forschungsinfrastrukturen dar – von der Datenextraktion und Korpuserstellung bis hin zur Analyse – und machen erstellte Skripte für alle zugänglich. Ferner verwenden wir offene und freie Tools für die Analysen. Damit soll es im Sinne von «open science» allen Forscher_innen ermöglicht werden, selbst mit diesen Forschungsinfrastrukturen und deren Datenbeständen zu arbeiten, die sich nicht zwangsläufig auf das Quantifizieren beschränken müssen. Bei der Forschungsinfrastruktur handelt es sich um das Open-Access-Fachrepositorium der Medienwissenschaft media/rep/, das den meisten Leser_innen als Fundstelle für wissenschaftliche Literatur bekannt sein dürfte. Über das durchsuchbare Archiv an Volltexten hinaus bietet die digitale Infrastruktur, die Repositoriumssoftware DSpace,3 eine große Vielzahl an Möglichkeiten, die Daten und Metadaten zu extrahieren, zu strukturieren und sie analytisch zu verwenden.
Bevor wir auf die Korpuserstellung und die methodischen Erwägungen eingehen, stellen wir media/rep/ als eine Forschungsinfrastruktur vor, die auch Gegenstand von Forschung sein kann bzw. je nach Profilierung des jeweiligen Korpus zahlreiche potenzielle Forschungsgegenstände beinhaltet. Abschließend legen wir einige exemplarische Ergebnisse möglicher Analysen dar, um die Potentiale derartiger methodischer Zugriffe zu illustrieren.
media/rep/ als Repositorium
«media/rep/ – das Repositorium für die Medienwissenschaft» ist eine Kooperation des Instituts für Medienwissenschaft mit der Universitätsbibliothek der Philipps-Universität Marburg.4 Es wird seit 2017 von der DFG gefördert, seit 2018 ist es online zugänglich. Seitdem wird es kontinuierlich anhand der fachlichen Anforderungen der kulturwissenschaftlichen Medienforschung wissenschaftsgetrieben weiterentwickelt. In einer ersten Phase (bis 2020) wurde die Grundstruktur des Repositoriums – bestehend aus den Bereichen «Aufsätze», «Bücher», «Online-Lehre», «Schriftenreihen», «Vorlesungen» und «Zeitschriften» – entwickelt.5 Neben den ‹klassischen› Textpublikationen wurde in dieser Phase zudem die Aufnahme von Videos (z. B. Vortragsaufzeichnungen) ins Repositorium erprobt und implementiert. In einer zweiten Phase (seit 2021) wird der Textbestand von media/rep/ kontinuierlich erweitert, wobei neben einer fachlichen Ausdifferenzierung (insbesondere der Periodika) nach medienwissenschaftlichen Forschungsfeldern zunehmend eine Internationalisierung des Datenbestandes maßgeblich ist. Ferner wird in dieser Phase der Bestand an Videos erheblich ausgebaut, und auch die Aufnahme von Audio-Dateien in das Repositorium ist mittlerweile möglich.6 In enger Abstimmung mit «NFDI4Culture», einem Konsortium der Nationalen Forschungsdateninfrastruktur, wurde darüber hinaus ein Forschungsdatenrepositorium entwickelt, das seit Oktober 2023 zur Verfügung steht.7 In technischer Hinsicht basierte media/rep/ bisher auf der Repositoriums-Software DSpace 6, wurde aber gemeinsam mit der Entwicklung des Forschungsdatenrepositoriums auf DSpace 7 migriert, was – aufgrund der semantischen Datenmodellierung, die Relationen zwischen Objekten herstellt, von DSpace 7 – perspektivisch interessante (Forschungs-)Möglichkeiten für weitere Nutzungen eröffnet.
Als Fachrepositorium8 nimmt media/rep/ Publikationen auf, die aus der Medienwissenschaft sowie angrenzenden Disziplinen stammen. Leitend ist dabei das Sammlungsprofil, das sich aus einem medienkulturwissenschaftlichen Selbstverständnis speist und das immer wiederdiskutiert und reflektiert wird, etwa im Projekt selbst oder mit dem Beirat.9 Dementsprechend ist media/rep/ bestrebt, Publikationen aufzunehmen, die für die deutschsprachige Medienkulturwissenschaft – als Teil einer internationalen Medienkulturwissenschaft – aus inhaltlicher, fachlicher und fachhistorischer Perspektive relevant sind. Auch wenn media/rep/ dezidiert keine Kanonisierung der Medienwissenschaft betreiben möchte, so gilt auch hier, dass aus dem Versuch, die Publikations- und Forschungskultur eines Fachs möglichst adäquat abzubilden, gewisse Kanonisierungseffekte erwachsen.10 Zugleich macht es die Versammlung, Systematisierung und Metadatisierung aber möglich, das Repositorium nicht ‹nur› zu nutzen, um Texte für die eigene Forschung und Lehre effizient zu finden, sondern media/rep/ auch als ‹Forschungstool› zu verwenden.11 Die folgenden methodischen Überlegungen und Schritte möchten aufzeigen, auf welche Weise die Datenbestände von media/rep/ für die medienwissenschaftliche Erforschung des eigenen Faches (z. B. in Bezug auf die Fachgeschichte) genutzt werden können.
media/rep/ als Untersuchungsgegenstand
media/rep/ weist formal und inhaltlich einen vielfältigen Datenbestand auf. So liegen die einzelnen Elemente wie Text (z. B. PDF), Audio (MP 3) und Video (MP 4 und WebM) nicht nur in verschiedenen Dateiformaten vor, sondern decken darüber hinaus unterschiedliche medienwissenschaftliche Publikationsformate ab. Unter den Audios befinden sich bisher ausschließlich Podcasts, wohingegen die Videos Vortragsaufzeichnungen, Diskussionsrunden und Interviews umfassen. Zum jetzigen Zeitpunkt wohl am interessantesten, da nicht zuletzt am umfangreichsten, dürften die Textpublikationen sein, die sich für datengestützte Analyseverfahren eignen, auf die wir uns in den folgenden Ausführungen konzentrieren. Von den aktuell ca. 19.300 Items in media/rep/ sind über 18.000 Texte, die sich wie folgt weiter auffächern: ca. 14.500 Zeitschriftenbeiträge, ca. 2.800 Aufsätze (aus Sammelbänden), ca. 900 Bände von Schriftenreihen (in der Regel Monografien) und ca. 450 vollständige Bücher, die nicht Reihen angehören.12 Daran zeigt sich, dass unselbstständige Schriften quantitativ deutlich gegenüber selbstständigen dominieren und insbesondere die Periodika hervorstechen. Letztgenannte sind fachhistorisch besonders interessant, begleiten sie die deutschsprachige Medienkulturwissenschaft doch teilweise seit ihren Anfängen – wie z. B. MEDIENwissenschaft: Rezensionen | Reviews – oder reichen gar weiter zurück – wie z. B. Rundfunk und Geschichte.13 Neben fachhistorischen Fragestellungen erlaubt es der Datenbestand von media/rep/ aber auch, zentrale Diskurse der Fachgesellschaft anhand der Zeitschrift für Medienwissenschaft als zentralem Publikationsorgan nachzuverfolgen oder Tendenzen innerhalb medienwissenschaftlicher Forschungsfelder wie der IMAGE für die Bildwissenschaft nachzugehen, um nur einige Beispiele zu nennen.14
Die Publikationen machen jedoch nur einen Teil des Datenbestandes von media/rep/ aus. Den anderen Teil stellen die Metadatensätze dar, die zu jeder Publikation vorliegen und diese sachlich wie formal beschreiben und um Identifier anreichern.15 Die Identifier wie DOI, ISSN, ISBN oder Normdaten der Gemeinsamen Normdatei (GND) und von Wikidata erlauben die Verbindung des Datenbestands mit weiteren Entitäten und ermöglichen somit, den Bestand im Sinne des Semantic Web mit weiteren Datenbanken zu vernetzen. Die Metadaten folgen dem Dublin Core-Schema, das sich weltweit als Standard durchgesetzt hat.16 Für die Generierung größerer Korpora spielen die Schnittstellen von media/rep/ eine entscheidende Rolle, weil so der Zugriff auf die strukturierten Daten ermöglicht wird. Für das Harvesting der Metadaten steht z. B. eine OAI-PMH-Schnittstelle zur Verfügung.17 Daneben existiert eine REST-Schnittstelle.18 Beide Schnittstellen lassen sich durch spezifische Skripte adressieren und gestatten größere Datenabfragen für Außenstehende. Im Sinne von «open science» sind also nicht nur die Texte selbst frei verfügbar, sondern auch die Metadaten, und die Datenstruktur selbst ist jederzeit für Außenstehende über das Internet nutzbar.
Diese Pluralität an Quellen, Daten und Formaten bietet eine optimale Grundlage für eine Bearbeitung mit medienwissenschaftlichen Fragestellungen und digitalen Methoden. Nachfolgend gehen wir auf zwei Beispiele für einen Auswertungsprozess mittels Text Mining ein.
Textanalyse zur Entwicklung der Fachgeschichte: Korpus, Methodik und Auswertung
Unsere analytische Arbeit am media/rep/-Bestand verfolgte von Beginn an ein methodisches und ein inhaltliches Ziel. Einerseits wollten wir datengestützte Analyseverfahren mit dem vorliegenden Material erproben und andererseits mithilfe dieser Analysen die fachhistorischen Perspektiven der (deutschsprachigen) Medienwissenschaft erkunden. In Bezug auf den Textbestand von media/rep/ ist dabei zu berücksichtigen, dass media/rep/ nur sieben Bücher außerhalb von Schriftenreihen beinhaltet, die vor dem Jahr 2000 erschienen sind, gegenüber über 400, die seit der Jahrtausendwende veröffentlicht wurden. Ebenso verhält es sich bei den Aufsätzen (aus Sammelbänden) – nur elf stammen aus dem 20. Jahrhundert, wohingegen über 2.800 im neuen Millennium publiziert wurden. Das bedeutet, dass der Textbestand von media/rep/ vor 2000 fast ausschließlich Periodika umfasst.19 Diesen Umstand gilt es, bei Arbeiten mit dem gesamten Textbestand von media/rep/ zu bedenken. In den beispielhaften Analysen, die wir am Ende dieses Textes präsentieren, beziehen wir den gesamten Bestand an Texten in die Analyse ein.
Für die Korpuserstellung war es unumgänglich, informatische und datenwissenschaftliche Expertise einzubeziehen, um Datenextraktion und Preprocessing angemessen durchführen zu können.20 Eine Extraktion der Daten auf dem herkömmlichen Wege via Textdownload als PDF und Metadatendownload als BibTex (wie media/rep/-Nutzer_innen ihn kennen) war dabei aus verschiedenen Gründen nicht möglich. PDFs sind einerseits als Dateiformat für einen Massendownload zu datenintensiv und erfordern daher – selbst automatisiert – einen höheren Aufwand. Andererseits konnten auf diese Weise die Metadaten zu den Artikeln nicht mit extrahiert werden. Diese sind jedoch für die Strukturierung des Materials im Preprocessing zentral sowie selbst als Untersuchungsgegenstand von Relevanz. Da Volltexte und Metadaten als plain text auf dem Suchindexserver vorhanden sind, wurde eine Kopie des Suchindexes erstellt. Diese Variante ist weniger datenintensiv als der Massendownload von Dateien. Aber bei der Extraktion der Texte als JSONs21 zeigte sich, dass die vorhandenen Server nicht für eine derartige Datenlast konzipiert sind, wie sie die Abfrage für eine Kopie erfordert. Da eine hardwaretechnische Auslagerung der Arbeitsleistung nicht möglich war, mussten die Abfragen segmentiert werden.22 So wurden die Texte inkl. Metadaten gestaffelt nach «dc.type» (Code in Dublin Core für den Publikationstyp) abgefragt, wobei der Suchindexserver z. B. bei der Abfrage nach dem Publikationstyp «book» zusammenbrach. Dies bedeutet, dass ein Gesamtabzug der Texte und Metadaten von media/rep/ nur möglich ist via Suchindex, wenn die datenintensiven Publikationstypen unterteilt nach «date.issued», ergo dem Publikationsjahr, abgefragt werden.23
Letztlich wurde aber davon abgesehen, dieses Verfahren der Datenextraktion via Suchindex anzuwenden. Es ist, wie beschrieben, sehr aufwändig und für Abzüge des Gesamtbestandes daher wenig praktikabel. Zudem ist dieses Vorgehen, im Sinne der open science, nicht angemessen, da nur das media/rep/-Team auf diese Weise auf die Daten zugreifen kann und Interessierte ausgeschlossen werden. Ferner erwies es sich als fehleranfällig: Erste stichprobenartige Überprüfungen zeigten, dass die Metadaten bei dem Abzug via Suchindex nicht vollständig waren. Deshalb - und auch um allen Interessierten den Zugriff zu ermöglichen - wurde ein Parsing-Skript in Python geschrieben, das auf die REST API von media/rep/ zugreift, um die Texte als TXTs und die Metadaten in einer CSV-Datei extrahieren zu können.24 Dieses Skript kann für Gesamt- sowie Teilabzüge des Datenbestandes verwendet werden.
Aufgrund des Datenumfangs des Gesamtbestandes von media/rep/ bedurfte das weitere Arbeiten mit den Daten jedoch einer stärkeren Vorstrukturierung des Textkorpus, bei der wir versuchten, Texte nach formalen Kriterien geordnet zu einer TXT zusammenzufassen. Dennoch wurde schnell klar, dass Analysetools wie Voyant25 mit der Beschaffenheit des Datenbestandes technische Probleme haben, sodass wir uns entschlossen, auf Python-Skripte via Jupyter Notebook auszuweichen26, mit deren Hilfe die folgenden Ergebnisse unter Rückgriff auf verschiedene Python-Programmbibliotheken gewonnen wurden. Ein Großteil der frei verfügbaren Tools27 ist für die Größe des media/rep/-Gesamtkorpus nicht geeignet, sondern bietet sich nur für die Beantwortung von Fragen zu Teilkorpora an (z. B. Analyse aller in media/rep/ vorhandenen Rezensionen oder Artikel, alle Publikationen eines bestimmten Zeitraums oder einer bestimmten Zeitschrift).
Exemplarisch präsentieren wir im Folgenden eine Analyse der Häufung von medienwissenschaftlichen Fachbegriffen im media/rep/-Gesamtkorpus. Hierzu haben wir ein Skript in der Programmiersprache Python entwickelt.28 Nach der beschriebenen Datenextraktion führten wir verschiedene Schritte des Textpreprocessings durch. In einem ersten Schritt fassten wir Publikationen basierend auf ihrem Publikationsjahr29 zu einer gemeinsamen Datei zusammen, sodass statt der über 18.000 Einzeldateien 54 nach Jahren geordnete Dateien vorlagen, wobei letzten Endes nur die zwischen 1980 und 2020 erschienenen Publikationen berücksichtigt wurden.30 Die zu analysierenden Dateien wurden in einem zweiten Schritt nach Stoppwörtern (z. B. Artikel, Konjunktionen, Präpositionen) gefiltert. Hintergrund dieses gängigen Verfahrens ist die Eliminierung von inhaltlich nicht relevanten Wörtern, was häufig die Analyse überhaupt erst ermöglicht, weil dadurch der Blick von den in jedem Text vorkommenden Wörtern auf jene gelenkt wird, die jeweils spezifisch sind. Die genutzte Stoppwortliste in Englisch und Deutsch wurde dem Textanalyse-Tool Voyant entnommen und durch weitere Wörter ergänzt, die spezifisch dem media/rep/-Korpus angepasst und für die Analyse nicht von inhaltlicher Bedeutung sind.31 Für eine weitere Bereinigung des Textes wurden zudem Wörter zusammengeführt, die sich aufgrund von Worttrennung am Zeilenende auf zwei Zeilen erstrecken. Zahlen sowie Nicht-Wort-Zeichen (Satzzeichen, Bindestriche etc.) und doppelte Leerzeichen, die für die Analyse der Texte irrelevant waren und in manchen Analyseschritten hinderlich wären, wurden entfernt. Die vorgenommene Umwandlung aller Großbuchstaben eines Textes in Kleinbuchstaben vereinfacht schließlich die Suche nach Wörtern, da ihre unterschiedliche Form in Groß- und Kleinschreibung nicht berücksichtigt werden muss.
Zur Analyse des so extrahierten und ‹bereinigten› Korpus verfolgten wir in einem explorativen Verfahren einen Text-Mining-Ansatz in Kombination mit Datenvisualisierungen in Python. Nachfolgend gehen wir auf zwei Analysemethoden und die damit gewonnenen Auswertungsergebnisse genauer ein. Einerseits betrifft dies die Verteilung von Worthäufigkeiten ausgewählter Fachbegriffe und ihre Aussagemöglichkeiten zur Entwicklung der Fachgeschichte anhand des Beispiels des Netz-Begriffs und andererseits die Repräsentation von Internet und Digitalität des media/rep/-Korpus.
Themenfeld Internet und Digitalität: Worthäufigkeiten und Trends
Das in media/rep/ vorliegende Textkorpus bietet sich für verschiedene Arten von inhaltlichen Analysen an, die sich mittels frei verfügbarer Textanalysetools wie Voyant oder durch die Entwicklung von Skripten in Programmiersprachen wie Python oder R durchführen lassen. Für die Analyse und Visualisierung von Worthäufigkeiten haben wir uns aufgrund der zuvor beschriebenen Parameter für die Arbeit mit Python-Skripten entschieden. Für die Verwaltung und Bereitstellung des Codes haben wir Jupyter Notebook und media/rep/ gewählt.
Im Rahmen des Artikels haben wir uns methodisch dafür entschieden, das Gesamtkorpus nach ausgewählten Begriffen zu durchsuchen, die für eine Untersuchung der film- und medienwissenschaftlichen Fachgeschichte im deutschsprachigen Raum relevant sein können. Dieses Verfahren folgt einer deduktiven Logik und dient der Überprüfung bereits bestehender Theorien/Annahmen. Als Beispiel diente die Fokussierung auf Begriffe und Trends zum Thema Internet und Digitalität. Bei der Definition der Suchbegriffe wählten wir Wortstämme, die einerseits für das Themenspektrum aussagekräftig genug sein sollten und andererseits mit verschiedenen Wortformen und Wortzusammensetzungen auftreten können. Auf diese Weise haben wir uns zunächst auf die Häufigkeiten der Nennung der assoziierten Suchbegriffe «digital*», «interakt*», «internet*», «netz*», «online*», und «virtu*» innerhalb des media/rep/-Korpus konzentriert und mithilfe eines Pythons-Skripts ausgeben lassen.32 Das «*» gibt an, dass in der Analyse nicht ausschließlich nach vollständigen Wörtern gesucht wurde, sondern im Sinne einer Wildcard-Suche nur der Beginn eines Wortes und damit verschiedene Wortendungsmöglichkeiten mitberücksichtigt wurden. So liefert eine Suche nach «interakt*» beispielsweise Ergebnisse zu« interaktionen», «interaktivität», «interaktives» etc. Folglich werden verschiedene Wortformen eines Wortstamms in der Suche mit abgedeckt sowie mit dem Suchbegriff zusammengesetzte Wörter, die selbst ein komplettes Wortfeld abdecken.33 Gleichzeitig birgt dieses Vorgehen jedoch das Risiko, dass ein stark verkürzter Suchbegriff Treffer generiert, die nicht dem gesuchten Wortfeld angehören. Beispielsweise haben wir «web*» als Suchbegriff wieder ausgeklammert, da er sich nicht auf Begriffe zum Thema World Wide Web beschränken lässt, sondern auch Begriffe wie weberei, webstuhl und weberianisch einschließt. In den wenigsten Fällen wird es sich vermeiden lassen, vereinzelte nicht dem Wortfeld zugehörige Begriffe in der Analyse zu finden. Relevant ist vielmehr, ob diese thematisch anders definierten Begriffe einen signifikanten Einfluss auf die Häufigkeitsermittlung ausüben. In Anbetracht der Größe des hier vorliegenden Textkorpus schlagen sich solche Einzelfälle bei den verbliebenen Suchbegriffen nicht sichtbar nieder.
Um das Aufkommen oder Verschwinden thematischer Schwerpunkte der Fachgeschichte zu untersuchen, haben wir uns die Häufigkeitsverteilungen zu den Suchbegriffen «digital*», «interakt*», «internet*», «netz*», «online*», und «virtu*» über den im Korpus abgedeckten Zeitraum von 1980 bis 2020 näher angeschaut. Die hierfür durchgeführte Analyse des Textkorpus besteht aus der Erstellung eines Dataframe, in dem die Häufigkeitsverteilung der jeweils gesuchten Wörter dargestellt wird, sowie einer graphischen Visualisierung in Form eines Liniendiagramms, das auch einen Einblick in die parallele Entwicklung zweier oder mehrerer Begriffe gewährt.34 Abb. 1 zeigt das Ergebnis unserer Abfrage.35
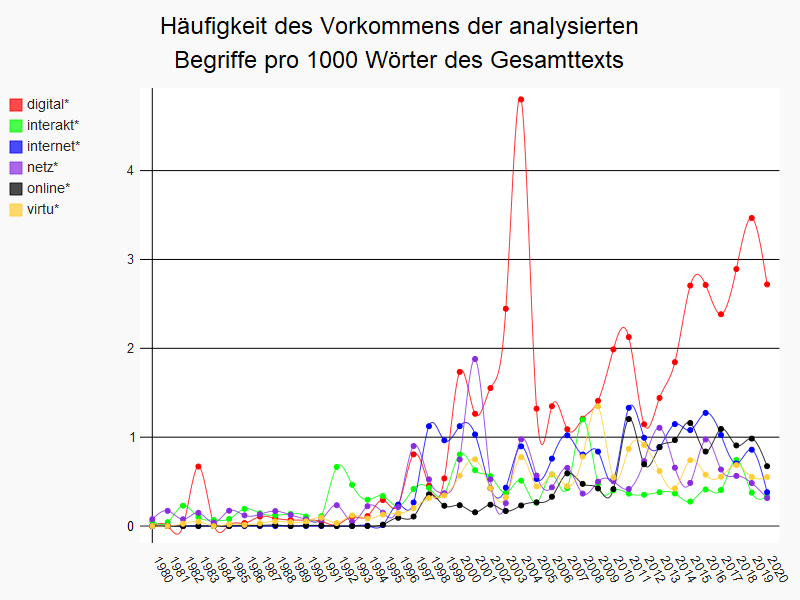
Abb. 1: Häufigkeit des Vorkommens der analysierten Begriffe pro 1000 Wörter des Gesamttexts
Die Datenmenge pro Jahr variiert im media/rep/-Bestand recht stark, sowohl was die Anzahl der Publikationen wie ihren Umfang angeht.36 Eine Analyse der absoluten Häufigkeit des Vorkommens von bestimmten Wörtern würde daher kein vergleichbares Ergebnis erzielen, weil einzelne Begriffe in größeren Textmengen schon rein statistisch häufiger vorkommen als in kürzeren Texten. Um eine Vergleichbarkeit zwischen den Texten der einzelnen Jahre zu ermöglichen, wurden daher relative Werte berechnet, indem die Häufigkeit des Vorkommens eines Suchbegriffes in Relation zum Gesamtumfang der Texte eines Jahres gesetzt wurde. Da eine derartige Umrechnung vielstellige Kommazahlen hervorbringt, ist es für ein leichteres Verständnis der angegebenen Werte zudem sinnvoll, die errechneten Zahlen in Bezug zu der Häufigkeit des Vorkommens eines Begriffes pro 100 oder 1000 Wörter zu bringen. Während eine Darstellung der Werte in Bezug auf 100 Wörter in einem Liniendiagramm eine feinrastigere Analyse ermöglicht, erschien es in diesem Kontext für einen intuitiveren Überblick sinnvoller, eine Darstellung in Relation auf 1000 Wörter zu wählen. So lässt sich beispielsweise für das gewählte Beispiel die Aussage treffen, dass der Suchbegriff «netz*» in den Texten von 2001 durchschnittlich 1,8-mal pro 1000 Wörter auftritt.37
Aus der direkten Gegenüberstellung der fünf Begriffe des gleichen Themenfeldes lassen sich verschiedene Trends erkennen. So gibt es eine generelle Häufigkeitszunahme aller Begriffe ab ca. 1996. Lediglich die Wortformen und Komposita zu «digital*» und «interakt*» bilden eine Ausnahme, da sie im ersten Fall bereits ab 1983 und im zweiten Fall ab 1991 punktuell häufiger verwendet wurden. Wenn wir uns den Auffälligkeiten der spezifischen Suchbegriffe zuwenden, werden weitere Feinheiten ersichtlich. Beispielsweise blieb die Häufigkeit von «online*» lange Zeit relativ niedrig, begann jedoch ab 2010 signifikant zu steigen und blieb anschließend vergleichsweise hoch. Im Gegensatz dazu zeigte «interakt*» bis auf die Spitzen in den Jahren 1992, 2000 und 2018 ein eher gleichmäßiges Nutzungsmuster. Die Häufigkeit von «internet*» verzeichnete einen starken Anstieg im Jahr 1998, nahm zu Beginn der 2000er Jahre ab und schwankte seitdem mit starken Ausschlägen. Auch die Derivate zu «virtu*» und «netz*» haben ein ähnliches wellenartiges Muster wie die «internet*»-Begriffe stabilisierten sich jedoch im Falle von «virtu*» ab 2015 mit wenigeren Häufigkeitsanomalien im Vergleich zu den anderen Begriffen. Die meisten Auffälligkeiten offenbart im direkten Vergleich die «digital*»-Familie. Neben dem sehr frühen Häufigkeitspeak im Jahre 1983 wurden Begriffe aus diesem Wortfeld ab der zweiten Hälfte der 1990er Jahre in regelmäßigen Abständen verwendet. Der besonders starke Ausschlag im Jahr 2004 korreliert wiederum mit Häufigkeitsspitzen bei fast allen anderen Suchbegriffen.38
Diese Beobachtungen aus einer Perspektive des Distant Readings laden dazu ein, sie durch zusätzliche Close Reading zu ergänzen, um die Gründe und Kontexte der diversen Häufigkeitsverteilungen zu verstehen. Unsere Diagramme sind somit als Teil des Analyseprozesses selbst zu betrachten und dienen nicht nur als Präsentation der Ergebnisse. Ähnlich verhält es sich mit der genaueren Untersuchung eines spezifischen Suchbegriffs aus dem genannten Themenfeld wie dem «netz*»-Begriff.
«netz*»-Begriffe: Formen und Zusammensetzungen
Ein besonders interessantes Wortfeld zum Thema Internet und Digitalität repräsentieren die Wortformen und -zusammensetzungen des Suchbegriffs «netz*». Anhand der Darstellung der 300 häufigsten Begriffe aus der «netz*»-Wildcard-Suche visualisierten wir mithilfe eines Python-Skripts die Häufigkeitsverteilung als Wortwolke.

Abb 2: «netz*»-Wortwolke
In dieser Präsentationsform werden zwei Aspekte unmittelbar ersichtlich. Zum einen sind in der Wortwolke unterschiedliche Wortformen und -zusammensetzungen des gleichen Wortstammes vertreten, beispielsweise «netz», «netze» und «netzen». Zum anderen überwiegen vor allem die beiden Substantiv-Wortstämme «netz» und «netzwerk», zu denen weitere Komposita zugeordnet werden können. Um die diversen Komposita zu beiden Begriffen genauer zu untersuchen, haben wir zwei weitere Wortwolken erstellt, in denen die flektierten Formen zu je etwa 300 Komposita zusammengefügt sind.
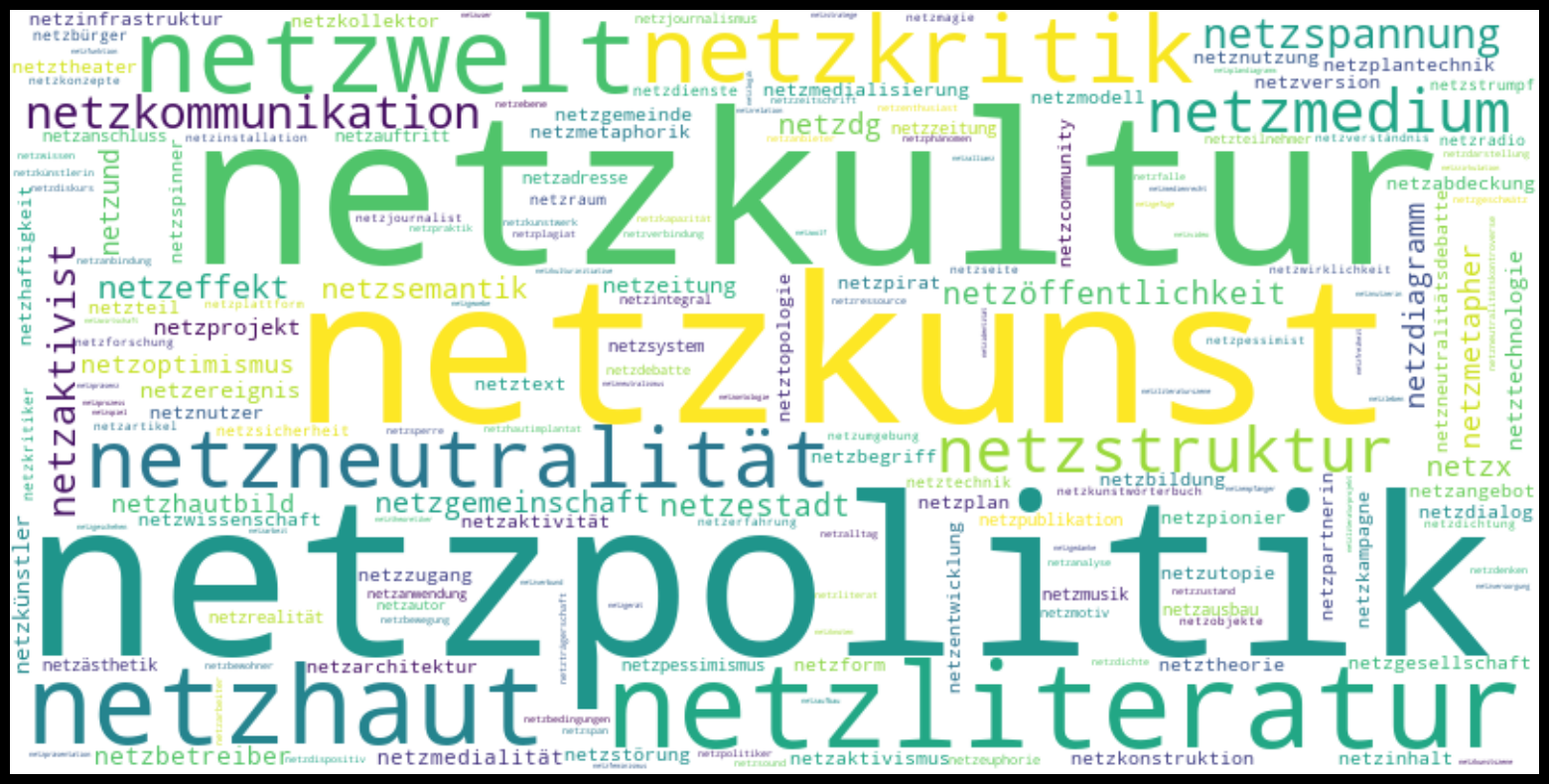
Abb 3: «netz»-Wortwolke
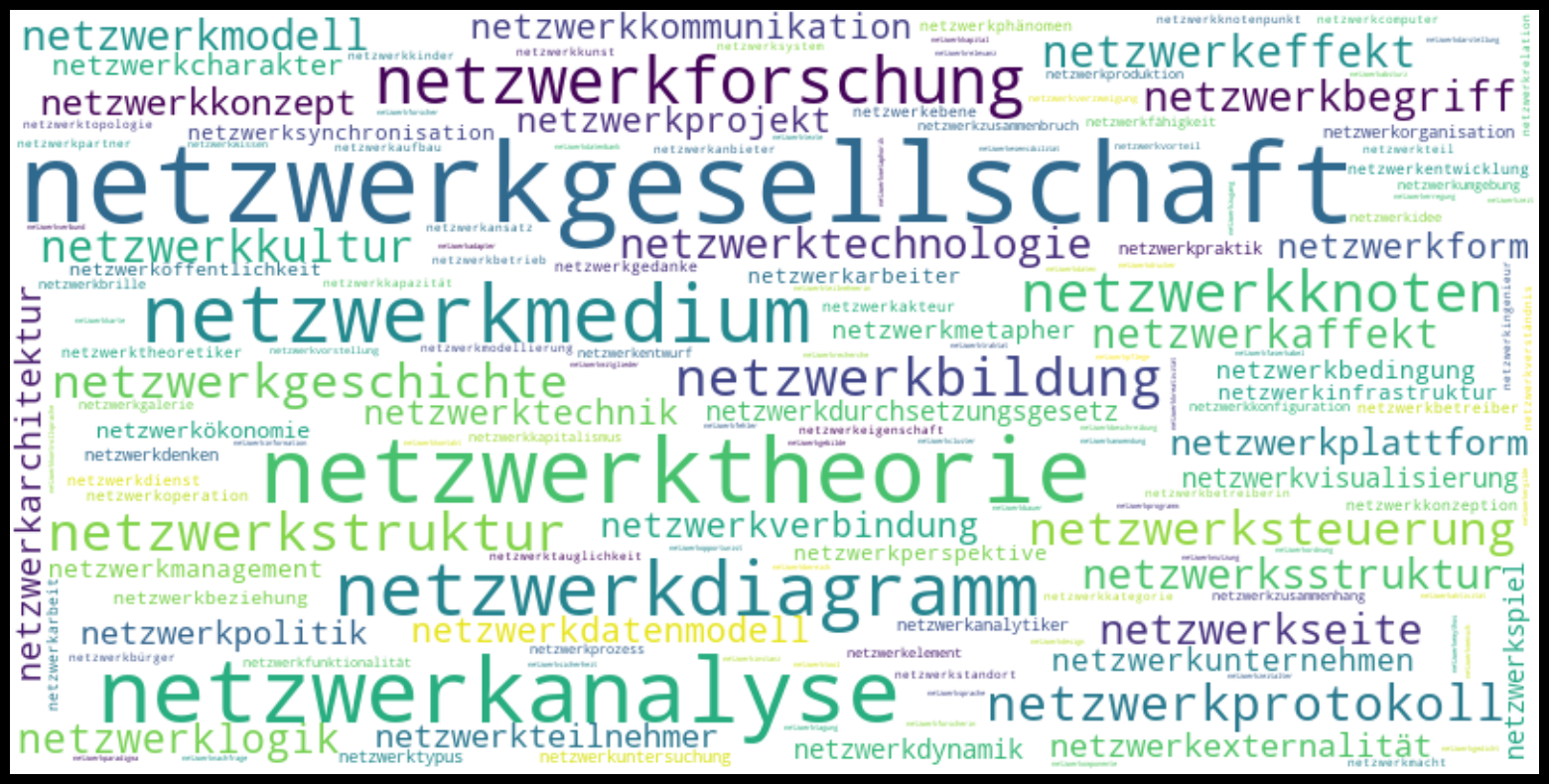
Abb 4: «netzwerk»-Wortwolke
In der Gegenüberstellung beider Wortwolken zeigt sich, dass das Netzwerk-Komposita-Wortfeld in den Häufigkeitsverteilungen feiner granuliert ist als das der Netz-Komposita.39 Die häufigsten Erwähnungen «netzwerkgesellschaft», «netzwerkanalyse» und «netzwerktheorie» sowie «netzkultur», «netzpolitik» und «netzkunst» liegen zudem thematisch nah beieinander. In einem nächsten Schritt wäre es daher interessant zu schauen, ob es weitere Korrelationen in den Texten selbst gibt. Aus der genaueren Betrachtung ähnlicher Daten, Häufigkeitsverteilungen und diagrammatischer Darstellungen lassen sich weitere Hypothesen zur Fachgeschichte der Film- und Medienwissenschaft auf Basis von media/rep/ entwickeln und überprüfen.
Fazit und Ausblick
Wie die vorgestellten Beispiele zeigen, erfordert die datengestützte Analyse der medienwissenschaftlichen Welt eine Offenheit für plurale Methoden und Zugänge. Anhand des Repositoriums für die Medienwissenschaft media/rep/ wurde aufgezeigt, welche Rolle bestehende Forschungsinfrastrukturen für die Verwaltung, Aufbereitung und Auswertung medienwissenschaftlicher Forschungsdaten und -fragen haben. Über die wichtige Aufgabe eines Repositoriums für Fachpublikationen hinaus kann media/rep/ unterdessen auch als Untersuchungsgegenstand selbst dienen. Die notwendigen Arbeitsschritte wie auch die erforderlichen disziplinübergreifenden Kenntnisse haben wir versucht, in diesem Beitrag offenzulegen.
Anhand des methodischen Vorgehens der Textanalyse zur Entwicklung der medienwissenschaftlichen Fachgeschichte haben wir gezeigt, wie sich die digitalen Bestände in media/rep/ mit digitalen Methoden explorativ auswerten lassen. Das Themenfeld Internet und Digitalität diente als Ausgangspunkt, um mithilfe eines Text Minings in Kombination mit Datenvisualisierung in Python die Trends zu thematisch verwandten Begriffen zu (re)präsentieren. Die Wortformen und Komposita zu netz* eignen sich als Beispiel, um aufzuzeigen, wie sich Datenvisualisierungen einsetzen lassen, um Wortfelder granular und binnendifferenzierend miteinander zu vergleichen.
Aus den vorgestellten Analyseansätzen und Beispielen geht hervor, dass es viele Anknüpfungspunkte und weiterführende Forschungsfragen gibt, die sowohl Perspektiven des Distant Readings als auch des Close Readings einbeziehen. Unser hier skizziertes Vorgehen zur Analyse der Fachgeschichte mithilfe eines selbstgewählten Themenfeldes kann als überwiegend deduktiv beschrieben werden. Eine alternative Herangehensweise wäre gewesen, die Häufigkeit aller im Korpus vorhandenen Wörter zu ermitteln und die am häufigsten vorkommenden Begriffe einer genaueren Analyse zu unterziehen, um hierdurch neue Thesen zur Entwicklung der Fachgeschichte zu bilden. Beide Vorgehensweisen lassen sich methodisch rechtfertigen. Letztgenannte Vorgehensweise bringt in Bezug auf die Größe des Textkorpus jedoch einige Herausforderungen mit sich, die für einen Einstieg in die Analyse des Gesamtkorpus nicht geeignet erscheinen. So ist die Zahl der im Korpus vorhandenen Wörter und ihrer Einzelformen auch nach der Entfernung von Stoppwörtern immens (über 1 Million) und wirft zusätzliche Fragen über die Definition von Stoppwörtern auf. Die Auseinandersetzung mit diesem Thema könnte dementsprechend einen eigenen Artikel füllen.
Mit diesem Aufsatz ist deshalb eine Einladung zur Arbeit mit den media/rep/-Beständen verbunden, die nicht auf Methoden der Textanalyse und Datenvisualisierung limitiert sein müssen. Mögliche Ansätze wären beispielsweise die Analyse von Zitationsnetzwerken oder Untersuchungen zur Gender-Verteilung unter den Autor_innen. Darüber hinaus wäre die Analyse aller in media/rep/ vorhandenen Rezensionen oder Artikel oder aller Publikationen eines bestimmten Zeitraums oder einer bestimmten Zeitschrift denkbar. Dabei sollte auch beachtet werden, dass nicht nur die Texte, sondern auch die Metadaten Gegenstand datengestützter Analysen sein können, wenn es z. B. um die Untersuchung der Verteilungen von Autor_innen nach Geschlechtern über einen Zeitraum hinweg geht. Derartigen Fragestellungen gehen wir in kommenden Publikationen nach.
- 1Vgl. dazu die Methoden-Debatte innerhalb der Publikationsorgane der Zeitschrift für Medienwissenschaft https://zfmedienwissenschaft.de/online/debatte/methoden-der-medienwissenschaft (22.11.2023); zu einer früheren Runde der fachpolitischen Diskussion siehe Rembert Hüser: Methoden der Medienwissenschaft (vorher). DFG-Workshop «Methoden der Medienwissenschaft» in Berlin, 11./12. März 2015, Thesenpapiere. In: Zeitschrift für Medienwissenschaft, 13.5.2015. URL: https://zfmedienwissenschaft.de/online/methoden-der-medienwissenschaft-vorher (22.11.2023). Vinzenz Hediger: Methoden der Medienwissenschaft (nachher): Wiederholte Kranzniederlegungen am Grabe Friedrich Kittlers sind kein Plan, in: Zeitschrift für Medienwissenschaft, 30.4.2015. URL: https://zfmedienwissenschaft.de/online/methoden-der-medienwissenschaft-nachher (22.11.2023) sowie Sven Stollfuß, Laura Niebling, Felix Raczkowski (Hg.): Handbuch Digitale Medien und Methoden, Wiesbaden 2024 (im Erscheinen).
- 2Zu Datenpraktiken in der Medienwissenschaft vgl. Marcus Burkhardt u. a. (Hg.): Interrogating Datafication: Towards a Praxeology of Data, Bielefeld 2022. DOI: https://doi.org/10.25969/mediarep/19165.
- 3https://dspace.lyrasis.org/ (22.11.2023).
- 4media/rep/ ist unter dem folgenden Link erreichbar: https://mediarep.org/ (22.11.2023). Für eine überblicksartige Darstellung zu media/rep/ vgl.Kai Matuszkiewicz: media/rep/ – das Open-Access-Fachrepositorium für die Medienwissenschaft, in: AKMB-news. Informationen zu Kunst, Museum und Bibliothek, Jg. 28, H. 2, 2022, 46–49.
- 5Vgl. dazu https://mediarep.org/community-list (22.11.2023).
- 6Vgl. dazu den Bereich «Podcasts» https://mediarep.org/handle/doc/17757 (22.11.2023).
- 7https://mediarep.org/communities/7e880a5a-5bcd-49b7-9b0e-ce4851b8d7bf. Vgl. zur Nationalen Forschungsdateninfrastruktur im Allgemeinen und zu NFDI4Culture im Besonderen https://www.nfdi.de/ sowie https://nfdi4culture.de/ (alle 22.11.2023).
- 8Zu Repositorien, Plattformen und Daten in der Medienwissenschaft vgl. Dietmar Kammerer, Kai Matuszkiewicz: Forschungsdaten in der Medienwissenschaft: Infrastrukturen, Plattformen und Forschungsdatenmanagement und ihre Bedeutung für die digitale Transformation der Medienwissenschaft, in: Sven Stollfuß, Laura Niebling, Felix Raczkowski (Hg.): Handbuch Digitale Medien und Methoden, Wiesbaden 2024 (im Erscheinen).
- 9Vgl. dazu das Selbstverständnis der GfM https://gfmedienwissenschaft.de/gesellschaft (22.11.2023).
- 10Vgl. dazu Arbeitskreis Kanonkritik: Welcher Kanon, wessen Kanon? Eine Einladung zur Diskussion, in: Zeitschrift für Medienwissenschaft, Jg. 14, Nr. 1, 2022, 159–171, hier 168. DOI: https://doi.org/10.25969/mediarep/18119.
- 11Vgl. dazu Dietmar Kammerer: Nicht nur suchen und finden, sondern entdecken und erforschen: Über das Open-Access-Repositorium media/rep/ als Werkzeug medienwissenschaftlicher Forschung, in: Open-Media-Studies-Blog. Zeitschrift für Medienwissenschaft, 14.12.2020. URL: https://zfmedienwissenschaft.de/online/open-media-studies-blog/nicht-nur-suchen-und-finden-sondern-entdecken-und-erforschen (22.11.2023).
- 12Stand 8.5.2023.
- 13Vgl. dazu https://mediarep.org/handle/doc/4958 sowie https://mediarep.org/handle/doc/19270 (beide 22.11.2023).
- 14Vgl. dazu https://mediarep.org/handle/doc/568 sowie https://mediarep.org/handle/doc/17173 (beide 22.11.2023).
- 15Zu Metadaten allgemein siehe Jeffrey Pomerantz: Metadata, Cambridge 2015.
- 16Vgl. dazu https://www.dublincore.org/specifications/dublin-core/ (22.11.2023). So sieht ein in media/rep/ erfasster Metadatensatz aus https://mediarep.org/entities/journalissue/eef0a858-0d3c-499c-8bd1-47ff379b4273/full (22.11.2023).
- 17Vgl. dazu https://mediarep.org/server/oai (22.11.2023). OAI-PMH steht für Open Archives Initiative Protocol for Metadata Harvesting.
- 18Vgl. dazu https://mediarep.org/server (22.11.2023). REST steht für REpresentational State Transfer und meint eine Programmierschnittstelle, die die Kommunikation zwischen Systemen erlaubt.
- 19Dies hängt einerseits mit der Fokussierung von Repositorien auf die aktuelle Forschungsliteratur zusammen und andererseits mit der Transformationsstrategie von media/rep/, die sich hauptsächlich an Periodika ausrichtet.
- 20Für die Arbeiten zur Datenextraktion sind wir Mathias Gutenbrunner und Eike Löhden aus dem Projekt media/rep/ zu großem Dank verpflichtet, genauso wie Marcel Förster aus dem Projekt DiCi-Hub für ihre jeweiligen Beiträge zur Vorbereitung des extrahierten Korpus.
- 21JSON steht für JavaScript Object Notation und ist ein Datenformat speziell für den Datenaustausch.
- 22HTTP GET-Abfragen erwiesen sich in diesem Kontext grundsätzlich als problematisch, HTTP POST-Abfragen hingegen als geeigneter, wenn auch sie nicht fehlerfrei waren.
- 23Dieses Vorgehen hat aber den angenehmen Nebeneffekt, dass derart die Daten bereits nach Jahren sortiert vorliegen - und somit für Analysen historischer Art bereits vorstrukturiert sind, die gewöhnlich die Texte eines Erscheinungsjahres zusammenfassen.
- 24Dieses Skript befindet sich, wie die übrigen Forschungsdaten des Projektes, im media/rep/ und kann nachgenutzt werden unter: https://doi.org/10.25969/mediarep/20185. Das Skript lässt sich via Terminal bzw. Kommandozeile starten und ausführen.
- 25Vgl. https://voyant-tools.org/ (22.11.2023).
- 26Vgl. https://jupyter.org/ (22.11.2023).
- 27Für die Analyse von Texten seien beispielsweise das bereits erwähnte Tool Voyant sowie textometry (TXM) (https://txm.gitpages.huma-num.fr/textometrie/en/) (22.11.2023) oder AntConc (https://www.laurenceanthony.net/software/antconc/) (22.11.2023) genannt. Die Tools unterscheiden sich bezüglich ihrer Anwendungsmöglichkeit auf unterschiedliche Dateiformate (TXT, XML), der Wiedergabe von Ergebnissen in unterschiedlichen (Visualisierungs-)Formen und der unterschiedlichen Kapazität für die Verarbeitung von großen Dateien. Die Wahl eines Tools muss daher immer auf dem Format der Ausgangsdaten und der Fragestellungen an die Daten basieren.
- 28https://doi.org/10.25969/mediarep/20185.
- 29Hiermit ist das eigentliche Publikationsjahr gemeint, nicht das Jahr, in dem die Publikation in media/rep veröffentlicht wurde.
- 30Die Anzahl der aus den davor liegenden Jahren gesammelten Publikationen ist deutlich geringer und erlaubt im Vergleich zu dem betrachteten Zeitraum nach 1980 nur eingeschränkte Aussagen. Da viele in media/rep/ veröffentlichte Publikationen mit einem gewissen Zeitverzug (u. a. bedingt durch Embargos) in das Repositorium eingehen, kann man für die 2020 nachfolgenden Jahre zum jetzigen Zeitpunkt noch nicht von einem vollständigen, repräsentativen Korpus sprechen. Daher bleiben diese Jahrgänge in dieser Analyse ebenfalls unberücksichtigt. Dies wird auch in der Betrachtung der hier vorliegenden Diagramme deutlich. In Abb. 1 z. B. fallen die dargestellten Kurven bereits 2020 im Vergleich zu den Vorjahren deutlich ab.
- 31Die Stoppwortliste sowie das für die Analyse genutzte Skript sind im media/rep/ verfügbar: https://doi.org/10.25969/mediarep/20185.
- 32Die in diesem Artikel präsentierten Abbildungen sind auch auf folgender GitHub-Seite einseh- und dowonloadbar: https://github.com/digitalcinemahub/projects/tree/main/dicihub_mediarep.
- 33Bei der Terminologie von Wortformen gibt es Feinheiten und Details, die in diesem Artikel nicht in Gänze behandelt werden können.
- 34Zur Erstellung des Dataframe wurde die Python-Library pandas verwendet: https://pandas.pydata.org/ (22.11.2023). Zur Erstellung der Diagramme wurde auf die Python-Library pygal zurückgegriffen: https://www.pygal.org/en/stable/ (22.11.2023).
- 35Die Visualisierung lässt sich unter dem Link https://github.com/digitalcinemahub/projects/blob/main/dicihub_mediarep/abb1_virtu_digital.svg im SVG-Format herunterladen. Durch Öffnen der Datei in einem geeigneten Grafikprogramm oder im Browser kann die Visualisierung mit dem Cursor interaktiv erkundet werden, was eine detaillierte Betrachtung ermöglicht.
- 36Anfangs- und Endpunkt des Untersuchungszeitraums verdeutlichen dies augenscheinlich. Aus dem Publikationsjahr 1980 befinden sich lediglich 4 Publikationen im media/rep/ mit insgesamt 80.106 Wörtern, wohingegen es für das Jahr 2020 717 Publikationen mit 6.232.030 Wörtern sind.
- 37Die Umrechnung und Darstellung der Werte ließen sich in verschiedenerlei Hinsicht weiter anpassen. Auch wenn relative Häufigkeiten im Gegensatz zu absoluten Häufigkeiten ein ausgewogeneres Gesamtbild zeigen, da sie die Größe der einzelnen Texte mitberücksichtigen, sind summierte relative Werte deutlich von vereinzelten Spitzen- und Niedrigstwerten in der Gesamtzahl der zu berücksichtigenden Werte beeinflusst und verschieben sich abhängig von diesen Einzelfällen deutlich nach oben oder unten. Wird beispielsweise die Häufigkeit eines Wortes in allen Einzeltexten eines Jahres erhoben und zu einer Gesamtsumme eines Jahres erfasst, würde der relative Wert für das Gesamtjahr bereits merklich ansteigen, wenn das Wort in der überwiegenden Zahl der Texte zwar durchschnittlich nur 1-mal pro 1000 Wörter vorkommt, aber in einigen wenigen Einzeltexten in der dreifachen Menge. Alternative Berechnungsmöglichkeiten stellen Mittelwert-Normalisierungen und die Errechnung von Z-Scores dar, die die Streuung und Abweichung von Werten mitberücksichtigen. Einen kompakten Überblick über die verschiedenen hier angesprochenen statistischen Grundlagen bietet Christof Schöch: Quantitative Analyse, in: F. Jannidis et al. (Hrsg.), Digital Humanities: Eine Einführung, 279-298, Stuttgart: Metzler, 2017.
- 38Eine Möglichkeit, derartige Häufigkeitsspitzen wie beim «digital*»-Wortfeld im Jahr 2004 zu erklären, stellt ein tiefergehender Blick in die Daten dar. Unter den 10 Publikationen mit den häufigsten Nennungen aus diesem Wortfeld befinden sich für das Jahr 2004 vier Monographien bzw. Sammelbände. Auf diese entfallen insgesamt 2.292 Nennungen der insgesamt 6.102 Nennungen in diesem Jahr. Somit sind bei der Interpretation von Häufigkeitsspitzen Textsortenspezifika sowie deren unregelmäßige Verteilung zu berücksichtigen.
- 39Da die Gesamtzahl an Netz-Komposita die für eine Wortwolke maximal geeigneten 300 Begriffe überschritt, sind in dieser Visualisierung alle einmaligen Vorkommen herausgenommen.
{kind=link}
Bildquellen
Teaserbild: Foto von Siora Photography auf Unsplash, 2018, https://unsplash.com/de/fotos/selektive-fokusfotografie-von-massbandern-cixohzDpNIo (7.12.2023)
Abb. 1: Grafik: «Häufigkeit des Vorkommens der analysierten Begriffe pro 1000 Wörter des Gesamttexts», erstellt von Autor*innen, 2023
Abb. 2–4: Wortwolken-Grafiken, erstellt von Autor*innen, 2023
Bevorzugte Zitationsweise
Die Open-Access-Veröffentlichung erfolgt unter der Creative Commons-Lizenz CC BY-SA 4.0 DE.