
Digitale Medien und Methoden
Über den methodischen Umgang mit visuellen Plattform-Inhalten und Internet-Memes
In unserem Beitrag Die Medienwissenschaft im Lichte ihrer methodischen Nachvollziehbarkeit haben wir (Laura Niebling, Felix Raczkowski, Maike Sarah Reinerth und Sven Stollfuß) dazu aufgerufen, über «gegenstandsbezogene Methoden und Ansätze» zu sprechen. Zur Vorbereitung auf das von uns in diesem Zusammenhang geplante Methoden-Handbuch Digitale Medien und als Beitrag zu einer offenen Methodendiskussion im Fach kuratieren wir in den kommenden Monaten eine Sonderreihe zu «Digitale Medien und Methoden» im Open-Media-Studies-Blog mit ‹Werkstattberichten› zu den in der medienwissenschaftlichen Forschung eingesetzten Methoden.
Der zwölfte Beitrag der Sonderreihe stammt von Elena Pilipets und beschäftigt sich mit visuellen und digitalen Methoden zur Untersuchung von Internet-Memes und deren Zirkulation in sozialen Netzwerken.
Tag, Like, Share: Weil Memes doch zirkulieren müssen
Auf sozialen Plattformen werden wir täglich mit Inhalten und Praktiken unterschiedlichster Art konfrontiert. Bilder, die online zirkulieren, stehen selten exklusiv für sich, sondern sind eingebettet in die Kommunikationslogik sozialer Plattformmedien. Internet-Memes als serielle Technobilder und vernetzte kommunikative Gesten des Social Web entstehen durch die Zirkulation und sind somit immer Teil von konfliktreich gelebten visuellen Plattformkulturen.
Dieser Blog-Beitrag diskutiert methodische Variationen im Umgang mit solchen user-generierten und plattform-distribuierten Bilderwelten unter Bedingungen einer affektiven Click-, Like- und Sharing Ökonomie. Dazu werden mithilfe einer Kombination aus visuellen und digitalen Methoden die relationalen Dateneigenschaften vernetzter Plattform-Inhalte angeeignet und im konzeptuellen Zusammenhang der media-native methods in Anlehnung an Richard Rogers und die Digital Media Initiative analysiert.
Dem Medium folgen: ‹Online-Groundedness› und dicht vermittelte Beschreibungen
Empirische Herausforderungen im Zusammenhang mit der Eingebundenheit von Bildern in technische Plattforminfrastrukturen sowie Überlegungen zu qualitativen wie quantitativen Ansätzen digitaler Bildforschung stehen seit einigen Jahren im Mittelpunkt der Diskussion rund um die Fragen: Auf welche Art werden wir durch technische Bilder dazu bewegt, plattformfokussierte Aufmerksamkeit zu erzeugen und wie mobilisieren wir eine plattformübergreifende Verbreitung von Bildern? So fragt die Bildforscherin Gillian Rose zum Beispiel: Wie zirkulieren diese Bilder und wie werden sie zirkuliert, sodass aus ihren Bewegungen stets neue Beteiligungsformen entstehen?
Plattformübergreifende Inhalte wie Internet-Memes, die darauf ausgelegt sind, Beteiligung zu intensivieren, können aus dieser Perspektive erst unter Berücksichtigung ihres soziotechnischen Netzwerkes verstanden werden. Bilder, die im Internet viral gehen, verbreiten sich nicht auf gleiche Weise. Sie werden unterschiedlich bereitgestellt, moderiert, bewertet und somit an unterschiedliche Datenspuren gebunden.
Sabine Niederer und Gabriele Colombo schlagen deswegen vor, visuelle Plattforminhalte als Objekte in Gruppen zu betrachten. Der Umgang mit relationalen Dateneigenschaften von Bildern entspringt dabei immer der praktischen Situation ihrer Nutzung auf sozialen Plattformen: Das Bereitstellen von Bildern in inhaltlichen Feeds nach verschiedenen Suchanfragen sowie ihr Teilen, Kommentieren und Liken spiegelt sich wieder im Prozess des Extrahierens von Bild-Daten mithilfe von API-spezifischen Werkzeugen. Das Sortieren von Inhalten in Datentabellen und Ordnern folgt danach zum Beispiel der zeit-, hashtag-, oder plattformspezifischen Logik der Bilddistribution und dient zur Vorbereitung für softwarebasierte Methoden der Visualisierung von Daten in Bilder-Netzwerken, -Plots, oder -Grids und Interpretation dieser in interdisziplinären Forscher_Innen-Teams. Was daraus resultiert, ist eine vielschichtig vermittelte Beschreibung des Phänomens, die durch mehrere multimediale und kollektive Beobachtungsschritte zugleich verdichtet und fabriziert wird.
Diese im Kontext der Digital Methods Initiative beschriebene Online-Groundedness von Medienartefakten ist zentral für das Verständnis digitaler Bilder als interaktive Datenpraktiken. Manche dieser Praktiken werden nun anhand eines am CAIS (Center for Advanced Internet Studies) in Bochum durchgeführten und im Rahmen von SMART Data Sprint am iNOVA Media Lab in Lissabon weiterentwickelten Projektes zur Nutzung von Internet-Memes im Kontext des Pornoverbots auf der sozialen Microblogging-Plattform Tumblr diskutiert.1
Kontext: Warum Moderation von Inhalten nie ‹safe› ist
Der kontroverse Fall des Pornoverbots auf Tumblr, auch Tumblr purge genannt, geht auf die Entdeckung von ungefilterter Kinderpornographie auf Tumblr im November 2018 zurück, woraufhin die neuen restriktiven Moderationsrichtlinien eingeführt wurden. Doch die ‹Säuberung› der Plattform von unangemessenen Beiträgen hatte problematische Folgen. Denn alle so genannten Erwachsenenbilder sowie ihre subkulturell relevanten Variationen und Hashtags wie #NSFW (not safe/suitable for work) sollten nach dem Vorfall algorithmisch identifiziert und aus den Suchergebnissen entfernt werden. Die ökonomisch motivierten Gründe für diese Entscheidung in Kombination mit offensichtlichen Fehlern bei der automatisierten Identifikation von Inhalten sorgten für berechtigte Empörung seitens der Nutzer_innen. Vor allem die Gleichsetzung von weiblichen Körpern mit Pornographie generierte negative Aufmerksamkeit: Der von Tumblr CEO Jeff D’Onofrio angekündigte Verbot von female-presenting nipples, ging viral – in einer Reihe von Screenshots, Memes und Hashtags, die sich gegen die Zensur richteten.
Die Verortung des heterogenen Bild-Materials
Eine wesentliche Herausforderung im Umgang mit heterogenen Mengen von Inhalten ist die Auswahl und Interpretation dieser nach bestimmten analytischen Kriterien. Die Verortung von Bildern in ausgewählten Hashtag-Formationen hilft dabei, den Kontext der Zirkulation besser zu verstehen und Daten entsprechend zu extrahieren. Aber wie lassen sich Bilder in ihren Beziehungen zueinander analysieren? Vor allem die Analyse von Internet-Memes geht oft mit der Frage einher: Aus welchen Beziehungen zwischen Plattform-Interaktionen, Nutzer_innen-Gemeinschaften und technisch grammatisierten Handlungen gehen sie hervor und wie werden sie dadurch transformiert?

Abb. 1 Eine Montage aus 15,158 Bildern, die zwischen November 2018 und August 2019 mit spezifischen Protest-Hashtags wie #censored, #tumblr purge und #female presenting nipples veröffentlicht wurden (visualisiert mithilfe des Image Montage Plugins von Image Plot).
Abbildung 1 präsentiert eine dynamische Sicht auf die Entfaltung von User_Innen-Kritik im Zuge der Pornographie-Zensur auf Tumblr. Diese als GIF formatierte Visualisierung kombiniert bildinterne (Farbton) und bildexterne (Zeit der Veröffentlichung) digitale Eigenschaften von 15,158 visuellen Beiträgen mithilfe von Image Plot, eines von Lev Manovich und Software Studies Initiative entwickelten visuellen Datenanalyse-Werkzeugs. Die softwarebasierte Anordnung von Bildern nach formalen Eigenschaften wie dem Farbton erleichtert die Interpretation von Wiederholungsmustern in heterogenen Bildarrangements. Werden die Bilder jedoch nach der Zeit geordnet und anschließend mithilfe manueller Exploration und maschineller Erkennung von Text im Bild kodiert, kann diese Methode vor allem dabei helfen, den spezifischen Rhythmus von visuellen Plattform-Interaktionen zu verstehen.
Die farbliche Markierung des Plots entspricht einem durch Nutzer_innen-Screenshots vermittelten Blick auf die von Tumblr im Laufe der Implementierung neuer Moderationsrichtlinien eingeführten Push-Mitteilungen. Diese wurden mit protestspezifischen Hashtags, ironischen Kommentaren und begleitenden Memes (alle im Plot nicht markierten Bilder) verbreitet. Abbildung 2 zeigt die Close-Ups von diesen Mitteilungen sowie ihre Distribution im Zeitraum zwischen November 2018 (die Ankündigung von neuen Moderationsrichtlinien) und August 2019 (der Verkauf von Tumblr an WordPress). Mithilfe eines Google Vision API-Moduls zur Wiedererkennung von Text im Bild konnten die vier Screenshot-Arten – (1) «community guidelines», (2) «contain adult», (3) «started following», (4) «was flagged» – nach der Häufigkeit ihrer Wiederholung pro Monat sortiert und in Form eines Diagramms visualisiert werden.
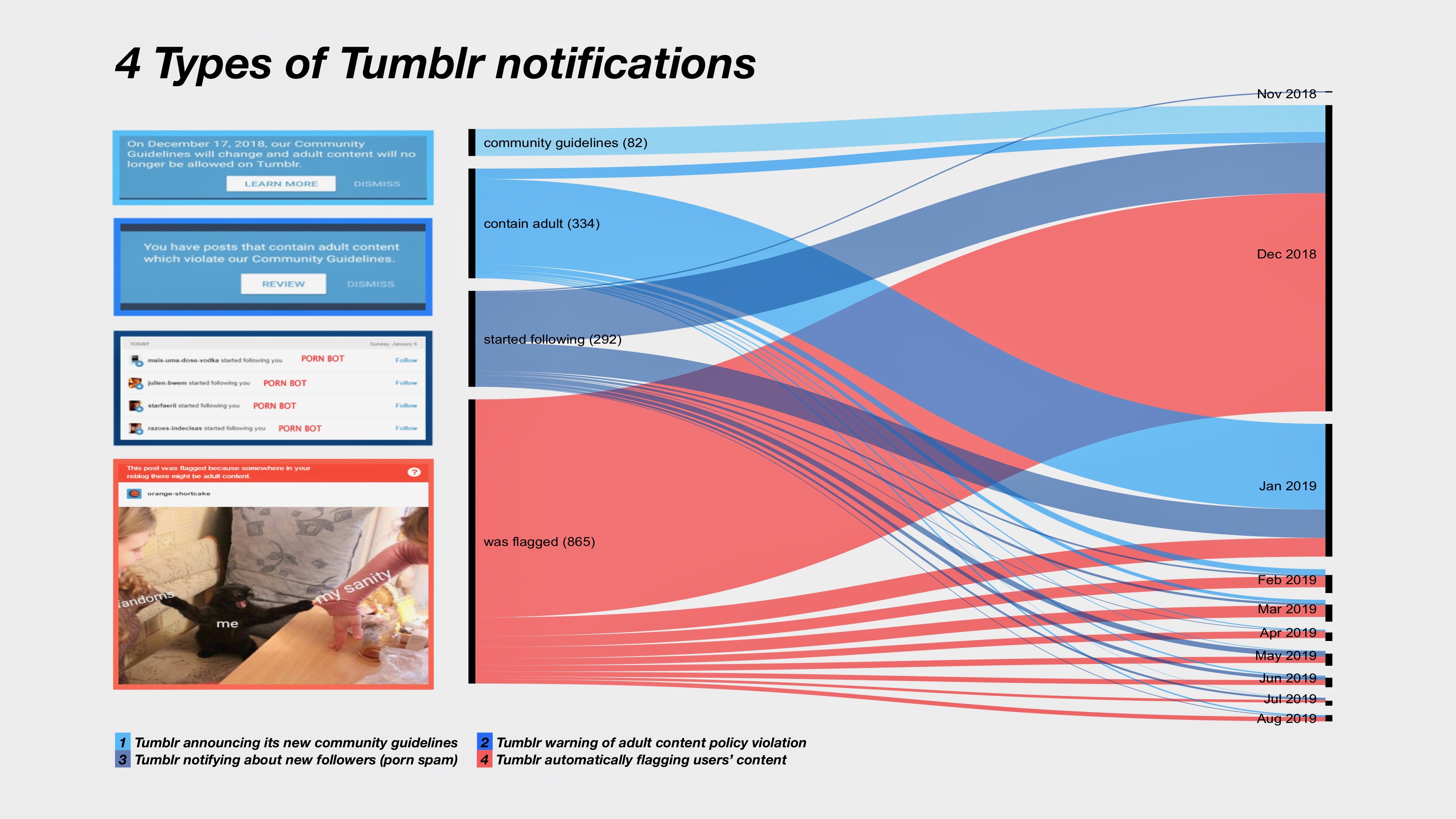
Abb. 2 Vier mithilfe von maschineller Erkennung von Text im Bild kodierten Arten von Screenshots, die Tumblr-Mitteilungen dokumentieren, und ihre Distribution über die Zeit (visualisiert mithilfe von RawGraphs).
Die überwiegende Anzahl von Inhaltsmeldungen (2) im Zusammenhang mit Screenshots von unzensierten pornographischen Spambots einerseits (3) und algorithmischen Fehlern bei der Identifikation von Nutzer_Innen-Inhalten andererseits (4) entspricht dem Höhepunkt der Kontroverse im Dezember 2018 kurz nach der Ankündigung von neuen Moderationsrichtlinien (1) und weist auf folgende wichtige Eigenschaft von Memes hin:
Sie entfalten ihre Resonanz in Beziehungen zu anderen kommunikativen Formaten des Social Web, indem sie abhängig von ihrem zeit- und plattformspezifischen Kontext denselben Inhalten eine neue Tonalität verleihen. Kontextspezifisch angepasste populäre Memes fungieren dabei nicht nur als ansteckende Formen der Partizipation, sondern auch als affektive Mittler, indem sie die situativen Haltungen, die sie transportieren, immer auch ein Stück mitverändern.
Memes als affektive Mittler und datenintensive Netzwerkartefakte
Wie lassen sich also die auf Tumblr zirkulierenden Protest-Memes in ihrer Rolle als Kritik von algorithmischen Interventionen verstehen? Dazu wurden drei im Dezember 2018 häufig wiederholten Memes durch die manuelle Exploration des Image Plots identifiziert. Um ihre situativen Variationen auf einen Blick nachvollziehbar zu machen, mussten wir die Bilder mithilfe eines anderen Bilderkennungsmoduls von Google Vision API nach den entsprechenden Web-Etiketten – «Surprised Pikachu», «Confused Anime Guy» und «Drakeposting» – filtern. Abbildung 3 präsentiert die sich daraus ergebende Anordnung von Bilderreihen nach der Intensität der Beteiligung mit jeder einzelnen Meme-Adaptation. Diese Methode erweist sich als hilfreich, wenn es darum geht, die kontextuellen Bildmodifikationen, die jeweils spezifische Bedeutung besitzen, als Teil eines ambivalenten memetischen Kollektivs zu analysieren.
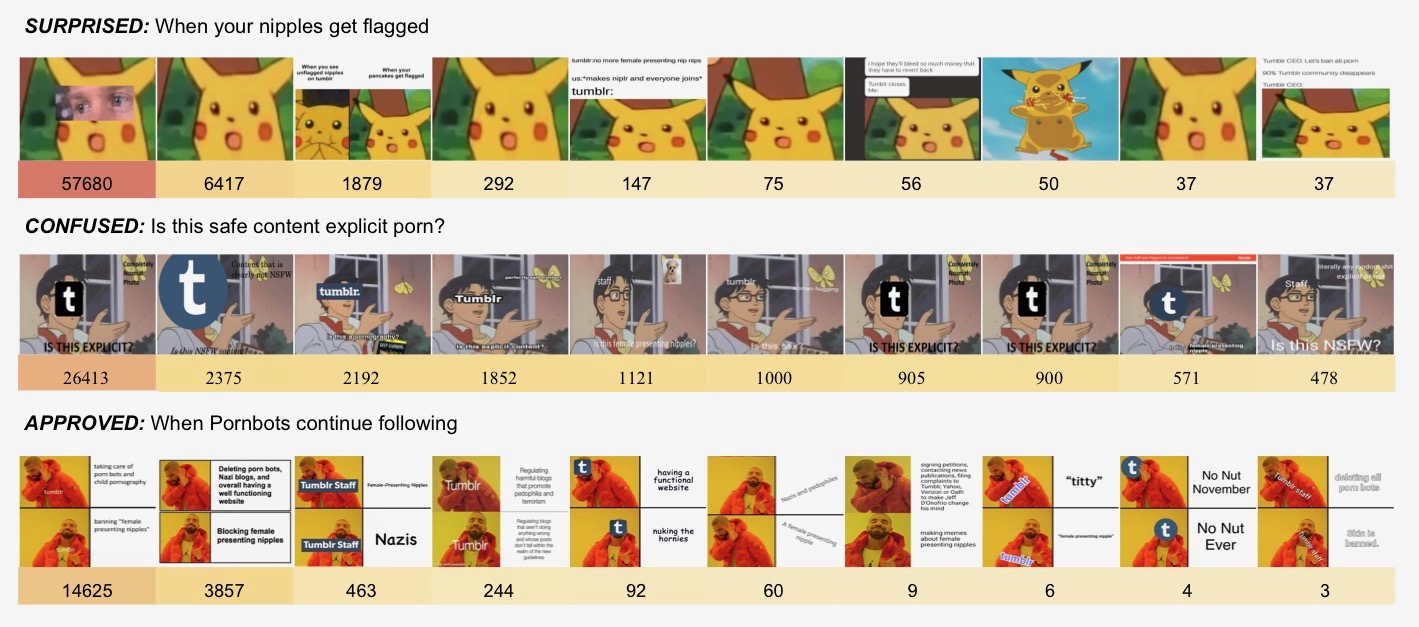
Abb. 3 Eine Auswahl von im Dezember 2018 am stärksten zirkulierten Meme-Reaktionen geordnet nach der Anzahl von Tumblr notes. Identifiziert mithilfe von Google Vision API vorgeschlagenen Etiketten (web entities). Visualisiert mithilfe von Google Spreadsheets.
Die in den Memes verdichteten Spuren der Bildaneignung während des Pornoverbots auf Tumblr machen sichtbar, was Olga Goriunova als individuation und Limor Shifman als stance konzeptualisiert haben: Surprised Pikachu steht für emotionale Reaktionen auf die Zensur von weiblichen Körpern und subkulturellen Inhalten. Confused Anime Guy fungiert als Mittel zur Ironisierung von algorithmischen Fehlern bei der Identifikation von Nacktheit. Drakeposting-Variationen verkörpern infrastrukturelle Blindheit von Tumblr den Pornobots und anderen problematischen Partizipationskulturen gegenüber.
Die affektiven Netzwerke, die in solchen memetischen Kollektiven entstehen, sind durch plattformisierte Metadaten verbunden (wie zum Beispiel Hashtags, die Anzahl von Likes und Kommentaren, etc.) und variieren sowohl in ihrer Haltung als auch in ihrer Intensität. So schaffen Tumblr-spezifische Note-Buttons, obwohl sie affektive Reaktionen in Form von Likes, Reblogs, Kommentaren und Rückmeldungen in einem Sammelwert quantifizieren, andererseits auch relational transformierende Beziehungen.

Abb. 4 Fragment eines kombinierten Hashtag-Bild-Netzwerks für 300 am stärksten zirkulierten Tumblr-Bilder die in Kombination mit Begriffen «NSFW» und «porn» geteilt wurden (visualisiert mithilfe von Table2Net und Gephi).
Abbildung 3 präsentiert diese Beziehungen in einem Netzwerk-Fragment von 300 mit den Begriffen «porn» und «NSFW» zirkulierten Bildern aus demselben Datensatz. Das Netzwerk zeigt eine durch #female presenting nipples, #tumblr purge und andere verwandte Protest-Hashtags assemblierte Bildgruppe, die mithilfe der Visualisierungssoftware Gephi analysiert wurde. Während die Größe einzelner Bilder der Anzahl von Tumblr-Notes entspricht, zeigt die Größe von Hashtags ihre kontextspezifische Relevanz: Je mehr Bilder mit bestimmten Hashtags gepostet wurden, desto präsenter waren diese Hashtags im Zuge der Entfaltung von Plattform-Kontroverse und desto größer erscheinen sie auch in der Visualisierung.
Die hohe Beteiligung rund um bestimmte Bilder (siehe zum Beispiel die populäre GIF-Adaptierung des Suprised Pikachu-Memes mit 57680 notes) kann somit als eine Art Seismograph für plattforminterne Aufmerksamkeitsdynamiken verstanden werden. Diese ziehen aber nicht nur weitere Likes, sondern auch andere Aktivitäten nach sich. Hashtags fungieren dabei als potenziell plattformübergreifende Netzwerk-Designer, die geteilte Inhalte relational versammeln und zirkulieren lassen.
Memes als zirkulative Partizipationspraktiken
Demnach sollte man fragen, wo und wie findet die Zirkulation von Bildern statt? Diese Frage ist nicht leicht zu beantworten und verlangt nach mehreren kombinierten analytischen Schritten, zum Beispiel mithilfe der Wiedererkennung von Bild-Motiven und ihren digitalen Kontexten durch maschinelles Sehen und anschließenden kritischen Interpretation dieser medial vermittelten Beschreibungen durch Forscher_innen.

Abb. 5 Fragmente aus zwei mithilfe von Google Vision API-Etiketten kreierten Bild-Netzwerken. Links: Ein Beispiel für referentielle Etiketten (web entities) für 500 #female presenting nipples Bilder. Rechts: Eine fokussierte Ansicht auf die Lokalisierung von Top-50 mit #tumblr purge geteilten Memes auf verschiedenen Plattformen (full matching images), darunter auch Pillowfort und andere im Kontext von Tumblr Zensur relevanten Seiten wie Twitter und Reddit (Visualisiert mithilfe von Memespector, Table2Net und Gephi).
Bilder-Netzwerke, die anhand der von Google Vision API vorgeschlagenen Etiketten web entities und full matching images Memes entweder nach den in den Bildern identifizierten Inhalten oder nach ihren übereinstimmenden digitalen Orten in Gruppen verorten, sind nicht nur experimentell, sondern auch durch mehrere Schichten der Vermittlung gekennzeichnet. Abbildung 5 kombiniert Fragmente solcher Netzwerke mit dem Fokus auf die Erkennung von memetischen Motiven (links) sowie die Distribution dieser Motive über die Grenzen der Plattformen hinaus (rechts).
Das Generieren, Beschreiben und Interpretieren solcher Netzwerke im Rahmen kollaborativer Forschungsprojekte ist ein iterativer Prozess, der im Anschluss an Situationsanalyse und Grounded Theory darauf abzielt, den kartographischen Zugang zu Daten als Datenpraktiken zu adaptieren. Bernhard Rieder und Carolin Gerlitz bezeichnen die analytischen Gesten, die damit einhergehen, als explorativ und zugleich grammatisiert. Jede analytisch verdichte Form der Datenvisualisierung vereint in sich so ein medial vermitteltes Netzwerk aus heterogenen Akteur_innen, darunter auch nicht-menschlichen.
Das kollektive Querlesen von Beziehungen zwischen visuellen, textuellen und materiellen Eigenschaften digitaler Inhalte mithilfe von verschiedenen Visualisierungsverfahren erlaubt uns so einerseits ein besseres situatives Verständnis von Plattformen, ihren soziotechnischen Umgebungen und ihren Partizipationskulturen. Andererseits beruht dieses Verständnis auf mehreren selektiven Schritten, die eine offene Situation der Zirkulation durch eine Ansammlung von Perspektiven verschiedener Art zu erfassen versucht. Solche Übergänge vermitteln nicht nur situatives Wissen, sondern stehen auch selbst im Zentrum der methodischen Reflexion. Gerade wenn es um die Voreingenommenheit von algorithmischen Empfehlungen bei der Erkennung von ambivalenten Inhalten wie Internet-Memes geht, braucht es mehrerer interpretativer Anläufe und interdisziplinärer Blickwinkel, um die Beziehungen zwischen den einzelnen Datenpunkten und ihren Kontexten kritisch zu rekonstruieren. Wie Forschungsprojekte zur Untersuchung von analytischen Möglichkeiten und Anwendungsgrenzen automatisierter Bilderkennung zeigen, sind Algorithmen weit davon entfernt, wertfrei zu sein. So ist auch der Übergang von Bildpraktiken der Nutzer_innen zu datenintensiven Archiven sozialer Plattformen zu technisch-vermittelten Formen ihrer Analyse niemals nahtlos. Als transaktionale Gefüge von soziotechnischen Aktivitäten sind Spuren digitaler Zirkulation immer auf eine gewisse Art zubereitet, was sie gleichzeitig zum Ausgangspunkt und zum Ziel der Analyse macht.
- 1Ich möchte mich bei allen Mitwirkenden, Ana Marta M. Flores, Giacomo Flaim, Monika Skazedonig, Rita Sepúlveda, Serena Del Nero und sowie bei Janna Joceli Omena für die Zusammenarbeit am CAIS und darüber hinaus, bedanken.
Bevorzugte Zitationsweise
Die Open-Access-Veröffentlichung erfolgt unter der Creative Commons-Lizenz CC BY-SA 4.0 DE.