
Open Your Heart
Simon David Hirsbrunner on reasons why media scholars might be reluctant to open their research data
In the media studies community, open science (OS) is often taken as a synonym for open access publishing. For someone like me, who investigates techno-scientific practice from an epistemological (or ‹STS›) perspective, such a narrow understanding of OS is not very rewarding. As other articles on the Open Media Studies blog have shown, open science goes beyond that and includes approaches such as Open Methodology, Open Source, Open Data, Open Access, Open Peer Review and Open Educational Resources 1. Some proponents of the OS movement go even further in proposing that these elements should be taken into consideration systematically and throughout the research cycle, which is often referred to as an ‹open research› approach. A corresponding program by the University of Exeter puts it this way:
Open research comprises openness throughout the research cycle, through collaborative working and sharing and making research methodology, software, code and equipment freely available online, along with instructions for using it.2.
The Wikipedia community has aptly defined open research as «research conducted in the spirit of free and open-source software.» 3. This points us to a general challenge encountered while experimenting with open science in media research: reading through the literature, it becomes apparent how strong OS is framed by the natural sciences, computer science, and quantitative methods. For example, an interdisciplinary group of researchers has published a great article addressing «how researchers understand and enact ‹openness› in their everyday working lives.»4. In the survey conducted for the study, researchers characterized openness as the opposite of ‹hiding,› ‹secrecy,› and ‹closing up.› The authors of the article identify seven core themes for the understanding, experiences, and practices of openness in science: the timely donation of and access to research components, standards for formats and quality of research components, metadata and annotation, freedom to choose venues and strategies for disseminating research components, transparent peer review systems, and access to research components in ‹non-western› and/or non-academic contexts.5.
Open science and digitalization
While most of these themes may equally be relevant for the field of media studies (e.g. transparent peer review systems, timely donation of and access to research components), the terminology used clearly emanates from the field and is tailored to the academic position of the interviewed researchers. The sample of interviewed scientists only includes principal investigators (PIs) aged approximately 35 to 60 years, who work in the fields of systems biology, synthetic biology, and bioinformatics. The sample may explain the crucial role of open data practices in this understanding of openness. However, a ‹digital› or ‹tech-fix› bias can be observed more broadly in OS literature. As I personally experience along an open science fellow program of the Wikimedia foundation, the discourses of open science and digitalization are mostly congruent, which can be illustrated by the many overlapping thematic foci in publications, biographies, and institutional affiliations of key actors. An example is the style-building anthology Opening Science. The Evolving Guide on How the Internet is Changing Research, Collaboration and Scholarly Publishing6, published by HIIG (Humboldt Institute for Internet and Society) and its researchers. If we’re proponents of a more value-conservative tradition in media studies (which I am not), some of the ideas discussed within these circles may evoke dystopian imaginaries of future (post-)scientific practice – as eternal wiki-writing in post-disciplinary structures, conducted collaboratively by human and non-human agents, in an ever traceable but anonymous blockchain structure (some snippets of this imaginary here). There goes the fame of the scientist (as we know her)… While fears of an all too open, all too digital science may eventually be unfounded, it seems important to consider and characterize the amalgamation of openness and digitality.
The OS movement is deeply rooted within the open knowledge community, where knowledge is understood as «open if anyone is free to access, use, modify, and share it — subject, at most, to measures that preserve provenance and openness.» (Open Knowledge Foundation 2019) It is of course an illusionary goal to enable «anyone» to access all kinds of scientific information. But open scientists may reach for ‹potentially anyone›, which is then translated to ‹the highest number of possible people (users)›. Openness becomes a quantifiable value, which then triggers desires for measurement. The strategic use of digital and online media technologies within the OS movement can then be perceived as a logical consequence: what is the vehicle that may potentially distribute scientific knowledge to anyone? Digital media. What infrastructure offers wide-ranging possibilities for the storage, transmission and processing of scientific knowledge? Internet. How to achieve more transparent and accountable scientific processes? Document everything freely online.
Mediality and open data
In my opinion, this equation of openness and digitality leads us to potential challenges we media researchers may face conducting ‹open research› in the sense of the eponymous discourse. These challenges have to do with our understanding of mediality and the pitfalls of amplification. In the following, I’d like to discuss these issues with the example of open data production, comparing such practices in the field of simulation modeling with those in my own (media) research.
Climate impact modelers conduct computer simulations to make statements about the relationships between human, earth and atmosphere in the past, present and future. The direct output of these in silico experiments7 is typically a digital dataset representing a series of data points indexed in time order (time series). Driven by scientific virtues and funding conditionalities, the climate modeler may then engage in open data practice in order to make her data better findable, accessible, inter-operable and re-usable. Open data practice in science is now formalized through these four characteristics referred to as the FAIR data principles for scientific data management and stewardship. The programmatic Nature article for FAIR states that:
There is an urgent need to improve the infrastructure supporting the reuse of scholarly data. A diverse set of stakeholders — representing academia, industry, funding agencies, and scholarly publishers — have come together to design and jointly endorse a concise and measurable set of principles that we refer to as the FAIR Data Principles. The intent is that these may act as a guideline for those wishing to enhance the reusability of their data holdings.8
The article also includes concrete recommendations on how to operationalize the making of FAIR data9:
To be Findable:
F1. (meta)data are assigned a globally unique and persistent identifier
F2. data are described with rich metadata (defined by R1 below)
F3. metadata clearly and explicitly include the identifier of the data it describes
F4. (meta)data are registered or indexed in a searchable resource
To be Accessible:
A1. (meta)data are retrievable by their identifier using a standardized communications protocol A1.1 the protocol is open, free, and universally implementable
A1.2 the protocol allows for an authentication and authorization procedure, where necessary
A2. metadata are accessible, even when the data are no longer available
To be Interoperable:
I1. (meta)data use a formal, accessible, shared, and broadly applicable language for knowledge representation.
I2. (meta)data use vocabularies that follow FAIR principles
I3. (meta)data include qualified references to other (meta)data
To be Reusable:
R1. meta(data) are richly described with a plurality of accurate and relevant attributes
R1.1. (meta)data are released with a clear and accessible data usage license
R1.2. (meta)data are associated with detailed provenance
R1.3. (meta)data meet domain-relevant community standards
How would our climate impact modeler proceed to implement these recommendations? She would certainly think about the best way to format her data, e.g. in a file standard used by her colleagues and other stakeholders relevant to her field (e.g. NetCDF for spatio-temporal temperature data). She would identify the best online data repository to store her data and make it accessible online. Moreover, she would spend much time to document the making of the dataset, its quality and eligibility for re-use. Depending on her project, our exemplary modeler would also include visual representations of the data inside the documentation or make the data itself explorable online. Ontologically, she will perceive her ‹open data› as just a representation of the simulation output data. She will unconditionally refrain from making changes to the data, as this would be considered scientific fraud.
In contrast, for media scholars, ‹open data› may be as much an oxymoron as ‹raw data›.10 We believe that media are productive – they do not only transmit an information, but produce a reality.11 They are mediators, not just intermediaries.12 In the case of open data, we as media scholars may not be able to detach the ‹raw data› (numerical representations) from its explicit or implicit meta-data (i.e. context, past), its embedding into (infra-)structures (present, situation), and its virtual qualities (the potential to enable future actions, agency, future). If we conceive media as a situated practice,13 the dichotomy of ‘closed data’ and ‘open data’ does not make much sense. Open and closed for whom exactly? In what kind of media environment? Where and when? For the climate modeler, these questions may trigger responses such as: ‹The data is accessible for many more people than before.› ‹Accessing the data takes less time than before.› ‹We had thousands of page views on our web platform›. We may reply that this is more about a mobilization, stabilization and amplification than about openness. The multiple actions undertaken by the climate modeler to open up her data may remind us of Bruno Latours cascade of inscriptions.14 ›Open data‹ is essentially the prospect of an immutable mobile,15 an entity that may potentially travel anywhere without loosing its essential shape. However, as Latour argues,16 opening up (amplification) always comes with a trade-off (reduction). In the process of data mobilization and standardization, we may gain compatibility and relative universality, but loose qualities such as locality, particularity, materiality, context and diversity. In every transformational step, we gain and loose something (see figure 1).
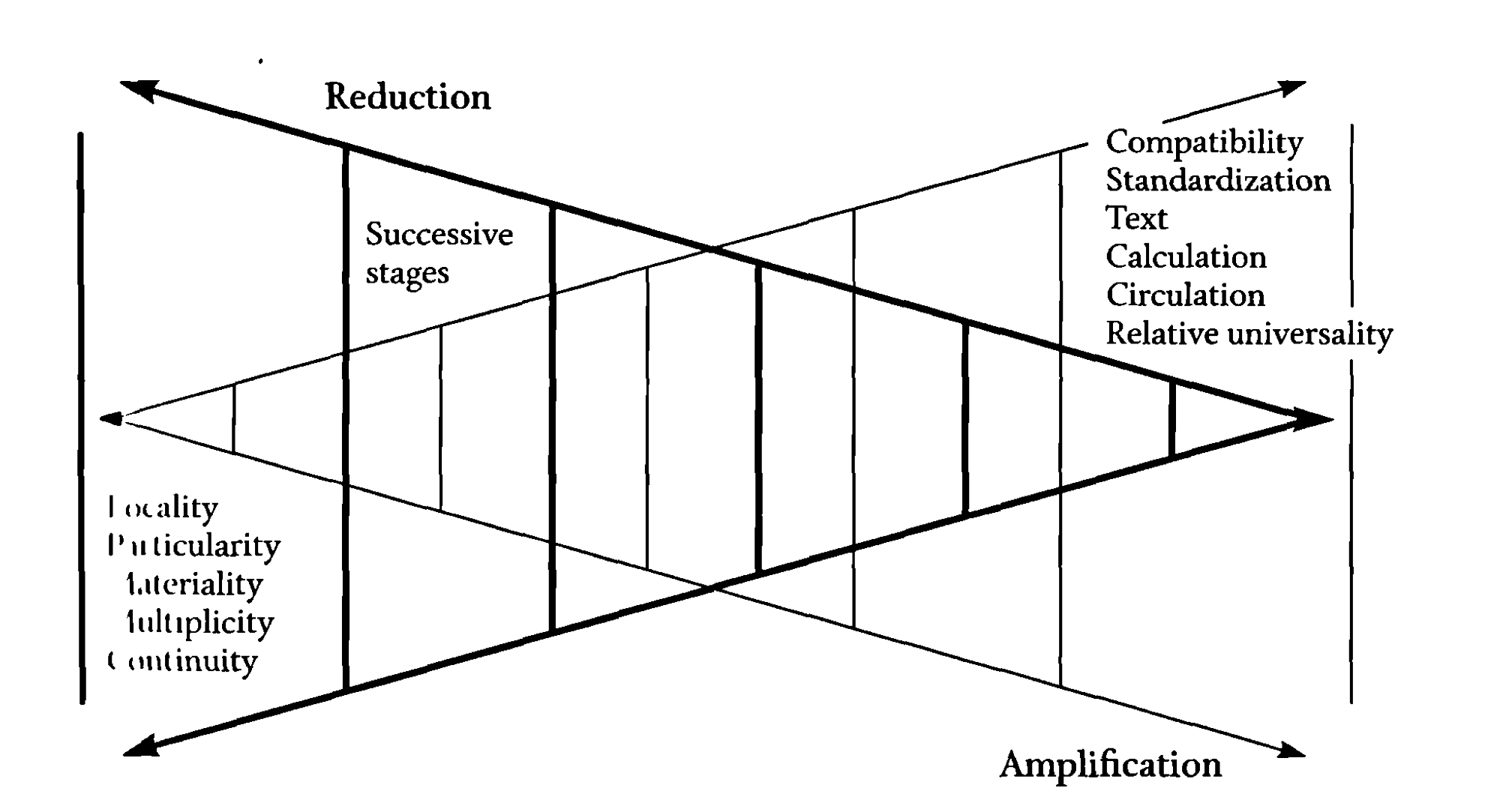
Figure 1: From Bruno Latour’s article «Circulating reference» in Pandora's Hope: «the transformation at each step of the reference […] may be pictured as a trade-off between what is gained (amplification) and what is lost (reduction) at each information-producing step.»17
As much as FAIR data is a noble objective and promising way to strive for open science in many academic fields (e.g. biology, computer science, physics), these principles may seem hard to work with for people handling qualitative or mixed (quant/qual) data, small data, highly heterogeneous, unstructured data, or analogue data. By ‹opening up› our heterogeneous research data, we may loose too many relationships, material qualities, histories, to sustain the present, but invisible structure of our dataset. We may loose a necessary safety space for imprecision18 and the essence of our research objects – their mediality or situatedness,19 which may act as starting points for further investigations into situated human cognition.
Open data – a discourse made for machines?
However, open data may not so much be an issue of human cognition as for machine readability, which is explicitly highlighted within the FAIR data program:
Distinct from peer initiatives that focus on the human scholar, the FAIR Principles put specific emphasis on enhancing the ability of machines to automatically find and use the data, in addition to supporting its reuse by individuals. (…)20
To a machine (and their human operators as proxies), the safety space for imprecision mentioned above may not exist. Data is either addressable or not, which may be translated to ‹open› versus ‹closed›. Open data is therefore unproblematic and a universal desideratum. For media scholars, in contrast, switching from closed to open data may be perceived as a heart operation, rattling at the essence of things.
«It's not that hard, if you just turn the key.» (Madonna in «Open Your Heart») [Screenshot]
- 1Peter Kraker u.a.: The Vienna Principles: A Vision for Scholarly Communication in the 21st Century, in: Mitteilungen Der Vereinigung Österreichischer Bibliothekarinnen Und Bibliothekare, Bd. 69, Nr. 3, 30.12.2016, 436.
- 2 University of Exeter website, last retrieved on 8 Feb 2019
- 3https://en.wikipedia.org/wiki/Open_research last retrieved on 8 Feb 2019.
- 4Nadine Levin u.a.: How do scientists define openness? Exploring the relationship between open science policies and research practice, in: Bulletin of science, technology & society, Bd. 36, Nr. 2, 2016, 128–141, here 129.
- 5Ibid., 132.
- 6Sönke Bartling, Sascha Friesike (Hg.): Opening Science, Cham 2014, online via http://link.springer.com/10.1007/978-3-319-00026-8, last retrieved on 9.4.2018
- 7Gabriele Gramelsberger: Computerexperimente: Zum Wandel der Wissenschaft im Zeitalter des Computers, Bielefeld 2008, 145 ff.
- 8Mark D. Wilkinson, Michel Dumontier, IJsbrand Jan Aalbersberg, Barend Mons u. a.: The FAIR Guiding Principles for Scientific Data Management and Stewardship, in: Scientific Data, Bd. 3, 15.3.2016, 160018, here 1.
- 9ibid., 4.
- 10Lisa Gitelman: «Raw Data» Is an Oxymoron, 2013.
- 11Knut Hickethier: Einführung in die Medienwissenschaft, Stuttgart Weimar 2010, 32.
- 12See Tristan Thielmann, Erhard Schüttpelz: Akteur-Medien-Theorie, 2013.
- 13Nick Couldry: Theorising media as practice, in: Social semiotics, Bd. 14, Nr. 2, 2004, 115–132.
- 14Bruno Latour: Circulating Reference, in: Pandora’s Hope: Essays on the Reality of Science Studies, Cambridge, Mass. 30.6.1999, 24–79.
- 15Bruno Latour: Visualisation and Cognition: Drawing Things Together, in: H. Kuklick (Hg.): Knowledge and Society Studies in the Sociology of Culture Past and Present, Bd. Vol. 6, o. O. 1988, 1–40.
- 16Bruno Latour: Zirkulierende Referenz, in: Die Hoffnung der Pandora, Frankfurt am Main 2000, 36–95.
- 17Bruno Latour: Zirkulierende Referenz, in: Die Hoffnung der Pandora, Frankfurt am Main 2000, 36–95, here 71.
- 18The term emanates from a discussion with information scientist Isabella Peters at a Wikimedia event on 15 Feb 2019.
- 19Donna Haraway: Situated Knowledges: The Science Question in Feminism and the Privilege of Partial Perspective, in: Feminist Studies, Bd. 14, Nr. 3, 1988, 575.
- 20Wilkinson et al.: The FAIR Guiding Principles for Scientific Data Management and Stewardship, 1.
Bevorzugte Zitationsweise
Die Open-Access-Veröffentlichung erfolgt unter der Creative Commons-Lizenz CC BY-SA 4.0 DE.